Artificial Intelligence and Machine Learning: Unit V: Neural Networks
ReLU
Neural Networks - Artificial Intelligence and Machine Learning
Rectified Linear Unit (ReLU) solve the vanishing gradient problem. ReLU is a non-linear function or piecewise linear function that will output the input directly if it is positive, otherwise, it will output zero.
ReLU
•
Rectified Linear Unit (ReLU) solve the vanishing
gradient problem. ReLU is a non-linear function or piecewise linear function
that will output the input directly if it is positive, otherwise, it will
output zero.
•
It is the most commonly used activation function in
neural networks, especially in Convolutional Neural Networks (CNNs) and
Multilayer perceptron's.
•
Mathematically, it is expressed as
f(x)
= max (0, x)
where
x : input to neuron
•
Fig. 10.8.1 shows ReLU function

•
The derivative of an activation function is required
when updating the weights during the back-propagation of the error. The slope
of ReLU is 1 for positive values and 0 for negative values. It becomes
non-differentiable when the input x is zero, but it can be safely assumed to be
zero and causes no problem in practice.
•
ReLU is used in the hidden layers instead of Sigmoid
or tanh. The ReLU function solves the problem of computational complexity of
the Logistic Sigmoid and Tanh functions.
•
A ReLU activation unit is known to be less likely to
create a vanishing gradient problem because its derivative is always 1 for
positive values of the argument.
•
Advantages of ReLU function
a)
ReLU is simple to compute and has a predictable gradient for the backpropagation
of the error.
b)
Easy to implement and very fast.
c)
The calculation speed is very fast. The ReLU function has only a direct
relationship.
d)
It can be used for deep network training.
•
Disadvantages of ReLU function
a)
When the input is negative, ReLU is not fully functional which means when it
comes to the wrong number installed, ReLU will die. This problem is also known
as the Dead Neurons problem.
b)
ReLU function can only be used within hidden layers of a Neural Network Model.
LReLU and ERELU
1.
LReLU
•
The Leaky ReLU is one of the most well-known
activation function. It is the same as ReLU for positive numbers. But instead
of being 0 for all negative values, it has a constant slope (less than 1.).
•
Leaky ReLU is a type of activation function that
helps to prevent the function from becoming saturated at 0. It has a small
slope instead of the standard ReLU which has an infinite slope.
•
Leaky ReLUs are one attempt to fix the "dying
ReLU" problem. Fig. 10.8.2 shows LReLU function.
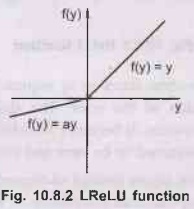
• The leak helps to increase the range of the ReLU function.
Usually, the value of a dog is 0.01 or so.
•
The motivation for using LReLU instead of ReLU is
that constant zero gradients can also result in slow learning, as when a
saturated neuron uses a sigmoid activation function
2.
EReLU
•
An Elastic ReLU (EReLU) considers a slope randomly
drawn from a uniform distribution during the training for the positive inputs
to control the amount of non-linearity.
•
The EReLU is defined as: EReLU(x) = max(Rx; 0) in the
output range of [0;1) where R is a random number
Artificial Intelligence and Machine Learning: Unit V: Neural Networks : Tag: : Neural Networks - Artificial Intelligence and Machine Learning - ReLU
Related Topics
Related Subjects

Artificial Intelligence and Machine Learning
CS3491 4th Semester CSE/ECE Dept | 2021 Regulation | 4th Semester CSE/ECE Dept 2021 Regulation