Database Management System: Unit I: Relational Databases
SQL Fundamentals
Relational Databases - Database Management System
Structure Query Language(SQL) is a database query language used for storing and managing data in Relational DBMS.
Part III: Structured Query Language
SQL Fundamentals
AU: Dec.-14,15,17,19, May-15,16,17,18, Marks 15
• Structure Query Language(SQL) is a database query
language used for storing and managing data in Relational DBMS.
• Various parts of SQL are -
• Data Definition Language(DDL): It consists of a set of
commands for defining relation schema, deleting relations, and modifying
relation schemas.
• Data Manipulation Language(DML): It consists of set of SQL
commands for inserting tuples into relational schema, deleting tuples from or
modifying tuples in databases.
• Integrity: The SQL DDL includes commands for specifying integrity constraints.
These constraints must be satisfied by the databases.
• View definition: The SQL DDL contains the commands for defining
views for database.
• Transaction control: The SQL also includes the set of commands that
indicate beginning and ending of the transactions.
• Embedded SQL and Dynamic SQL: There is a facility of including SQL commands in
the programming languages like C,C++, COBOL or Java.
• Authorization: The SQL DDL includes the commands for
specifying access rights to relations and views.
Data Abstraction
The Basic data types used in SQL are -
(1) char(n): For
representing the fixed length character string this data type is used. For
instance to represent name, designation, coursename, we use this data type.
Instead of char we can also use character. The n is specified by the user.
(2) varchar(n): The
varchar means character varying. That means - for denoting the variable length
character strings this data type is used. The n is user specified maximum
character length.
(3) int: For
representing the numeric values without precision, the int data type is used.
(4) numeric: For representing, a fixed point number with user-specified
precision this data type is used. The number consists of m digits plus sign k
digits are to the right of precision. For instance the numeric(3,2) allows 333.11
but it does not allow 3333.11
(5) smallint: It is used
to store small integer value. It allows machine dependent subset of integer
type.
(6) real: It allows the floating point, double precision numbers.
(7) float(n): For representing the floating point number with precision
of at least n digits this data type is used.
Basic Schema Definition
In this section, we will discuss various SQL commands for
creating the schema definition.
There are three categories of SQL commands.

Data Definition Language

Data Manipulation Language

Data Control Language

1. Creation
• A database can be considered as a
container for tables and a table is a grid with rows and columns to hold data.
• Individual statements in SQL are called queries.
• We can execute SQL queries for
various tasks such as creation of tables, insertion of data into the tables,
deletion of record from table, and so on.
In this section we will discuss how to create a table.
Step 1: We normally create a database using following SQL statement..
Syntax
CREATE DATABASE database_name;
Example
CREATE DATABASE Person _DB
Step 2: The table can be created inside the
database as follows -
CREATE TABLE table name (
Col1_name datatype,
col2 _name datatype,
……
coln_name datatype
);
Example
CREATE TABLE person_details{
AdharNo int,
FirstName VARCHAR(20),
MiddleName VARCHAR(20),
LastName VARCHAR(20),
Address VARCHAR(30),
City VARCHAR(10)
}
The blank table will be created with following structure
Person_details

2. Insertion
We can insert data into the table using INSERT statement.
Syntax
INSERT INTO table_name (col1, col2,...,coln)
VALUES
(value1,value,...., valuen)
Example
INSERT INTO person_details (AdharNo, FirstName,
MiddleName, LastName, Address, City)
VALUES (111, 'AAA','BBB','CCC','M.G. Road', 'Pune')
The above query will result into –

3. Select
• The Select statement is used to
fetch the data from the database table.
• The result returns the data in the
form of table. These result tables are called resultsets.
• We can use the keyword DISTINCT. It is an optional
keyword indicating that the answer should not contain duplicates. Normally if
we write the SQL without DISTINCT operator then it does not eliminate the
duplicates.
Syntax
SELECT col1, col2, ...,coln FROM table_name;
Example
SELECT AdharNo, FirstName, Address, City from
person_details
The result of above query will be

• If we want to select all the records present in the
table we make use of * character.
Syntax
SELECT FROM table_name;
Example
SELECT * FROM person_details;
The above query will result into

4. Where Clause
The WHERE command is used to specify some condition. Based
on this condition the data present in the table can be displayed or can be
updated or deleted.
Syntax
SELECT
col1,col2, ...,coln
FROM table_name
WHERE condition;
Example
Consider following table-
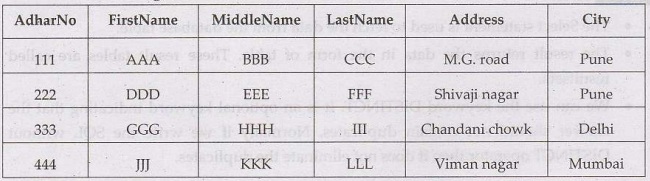
If we execute the following query
SELECT AdharNo
FROM person_details
WHERE city='Pune';
The result will be
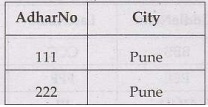
If we want records of all those person who live in city Pune
then we can write the query using WHERE clause as
SELECT
*
FROM person_details
WHERE
city='Pune';
The result of above query will be

5. Update
• For modifying the existing record of a table,
update query is used.
Syntax
UPDATE table name
SET col1-value1, col2-value2,...
WHERE condition;
Example
Consider following table
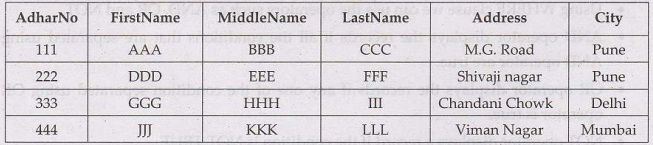
Person_details table
If we execute following query
UPDATE rerson_details
SET city 'Chennai'
WHERE AdharNo=333
The result will be
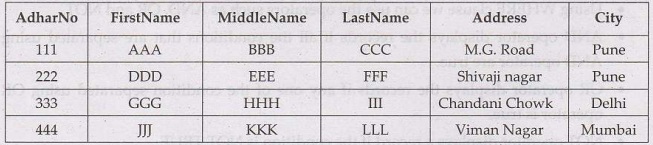
6. Deletion
We can delete one or more records based on some condition.
The syntax is as follows -
Syntax
DELETE FROM table_name WHERE condition;
Example
DELETE FROM person_details
WHERE
AdharNo=333
The result will be –

We can delete all the records from table. But in this deletion, all the
records get deleted without deleting table. For that purpose the SQL statement
will be
DELETE
FROM person_details;
7. Logical Operators
• Using WHERE clause we can use the
operators such as AND, OR and NOT.
• AND operator displays the records if
all the conditions that are separated using AND operator are true.
• OR operator displays the records if
any one of the condition separated using OR operator is true.
• NOT operator displays a record if
the condition is NOT TRUE.
Consider following table
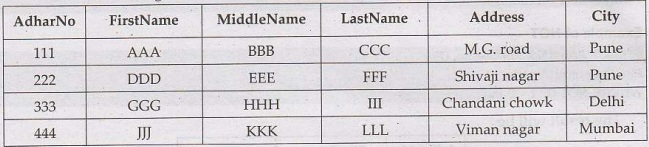
Syntax of AND
SELECT
col1, col2, ...
FROM table_name
WHERE condition1 AND condition2 AND condition3...;
Example
of AND
If we execute following query-
SELECT AdharNo, FirstName, City
FROM person_details
WHERE AdharNo=222 AND City= 'Pune';
The result will be –

Syntax of OR
SELECT
col1, col2, ...
FROM table_name
WHERE condition1 OR condition2 OR condition3 ...;
Example of OR
SELECT AdharNo, FirstName, City
FROM person_details
WHERE City='Pune' OR City='Mumbai';
The result will be –
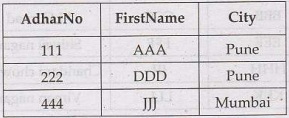
Syntax of NOT
SELECT
col1, col2, ...
FROM table_name
WHERE NOT condition;
Example of NOT
SELECT AdharNo, FirstName, City
FROM person_details
WHERE NOT City='Pune';
The result will be

8. Order By Clause
• Many times we need the records in the table to be
in sorted order.
• If the records are arranged in
increasing order of some column then it is called ascending order.
• If the records are
arranged in decreasing order of some column then it is called descending order.
• For getting the sorted records in the table we use
ORDER BY command.
• The ORDER BY keyword sorts the records in ascending
order by default.
Syntax
SELECT
col1, col2,...,coln
FROM table_name
ORDER BY col1,col2.... ASC | DESC
Here ASC is for ascending order display and DESC is for
descending order display.
Example
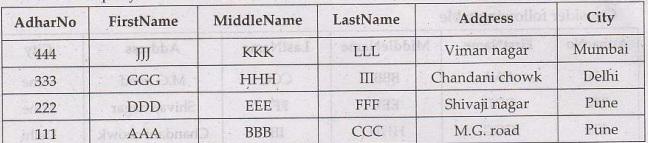
Consider following table
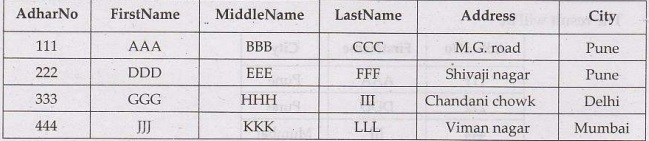
SELECT
*
FROM person_details
ORDER BY AdharNo DESC;
The above query will result in
9. Alteration
There are SQL command for alteration of table. That means we can add new
column or delete some column from the table using these alteration commands.z
Syntax for Adding columns
ALTER TABLE table_name
ADD column_name datatype;
Example
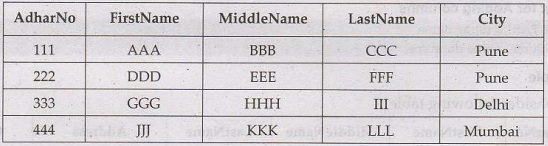
Consider following table

If we execute following command
ALTER TABLE Customers
ADD Email varchar(30);
Then the result will be as follows –
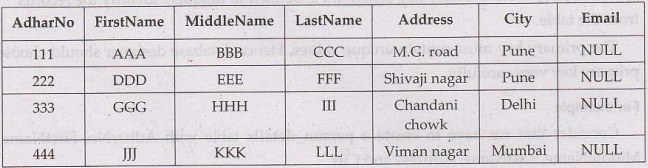
Syntax for Deleting columns
ALTER TABLE table_name
DROP COLUMN column name;
Example
Consider following table
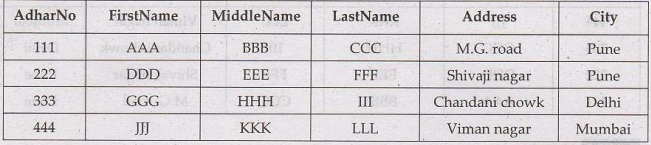
If we execute following command
ALTER TABLE Customers
DROP COLUMN Address;
Then the result will be as follows –
10. Defining Constraints
• We can specify rules for data in a table.
• When the table is created at that time we can
define the constraints.
• The constraint can be column level i.e. we can
impose constraint on the column and table level i.e we can impose constraint on
the entire table.
There are various types of constraints that can be defined are as
follows -
1) Primary key: The primary key constraint is defined to uniquely identify the records
from the table.
The primary key must contain unique values. Hence database
designer should choose primary key very carefully.
For example
Consider that we have to create a
person_details table with AdharNo, FirstName, MiddleName, LastName, Address and
City.
Now making AdharNo as a primary key is helpful here as using this field
it becomes easy to identify the records correctly.
The result will be
CREATE TABLE person_details (
AdharNo int,
FirstName VARCHAR(20),
MiddleName VARCHAR(20),
LastName VARCHAR(20),
Address VARCHAR(30),
City VARCHAR(10),
PRIMARY KEY(AdharNo)
);
We can create a composite key as a primary key using CONSTRAINT keyword.
For example
CREATE TABLE person_details (
AdharNo int NOT NULL,
FirstName VARCHAR(20),
MiddleName VARCHAR(20),
LastName VARCHAR(20) NOT NULL,
Address VARCHAR(30),
City VARCHAR(10),
CONSTRAINT PK_person_details PRIMARY KEY(AdharNo,
LastName)
);
(2) Foreign Key
• Foreign key is used to link two tables.
• Foreign key for one table is actually a primary key
of another table.
• The table containing foreign key is called child
table and the table containing candidate primary key is called parent key.
• Consider
Employee Table
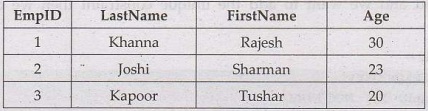
Dept Table:
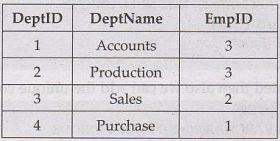
• Notice that the "EmpID"
column in the "Dept" table points to the "EmpID" column in
the "Employee" table.
• The "EmpID" column in the
"Employee" table is the PRIMARY KEY in the "Employee"
table.
• The "EmpID" column in the
"Dept" table is a FOREIGN KEY in the "Dept" table.
• The FOREIGN KEY constraint is used
to prevent actions that would destroy links between tables.
• The FOREIGN KEY constraint also prevents invalid
data from being inserted into the foreign key column, because it has to be one
of the values contained in the table it points to.
• The purpose of the foreign key constraint is to
enforce referential integrity but there are also performance benefits to be had
by including them in your database design.
The table Dept can be created as follows with foreign key constraint.
CREATE TABLE DEPT (
DeptID int
DeptName VARCHAR(20),
EmpID int,
PRIMARY KEY(DeptID),
FOREIGN
KEY (EmpID)
REFERENCES
EMPLOYEE(EmpID)
);
(3) Unique
Unique constraint is used to prevent same
values in a column. In the EMPLOYEE table, for example, you might want to
prevent two or more employees from having an identical designation. Then in
that case we must use unique constraint.
We can set the constraint as unique at the time of creation of table, or
if the table is already created and we want to add the unique constraint then
we can use ALTER command.
For example -
CREATE
TABLE EMPLOYEE(
EmpID INT NOT NULL,
Name VARCHAR (20) NOT NULL,
Designation VARCHAR(20) NOT NULL UNIQUE,
Salary DECIMAL (12, 2),
PRIMARY KEY (EmpID)
);
If table is already created then also we can add the unique constraint
as follows -
ALTER TABLE EMPLOYEE
MODIFY Designation VARCHAR(20) NOT NULL UNIQUE;
(4) NOT NULL
• By default the column can have NULL values.
• NULL means unknown values.
• We can set the column values as non NULL by using
the constraint NOT NULL.
• For example
CREATE TABLE EMPLOYEE(
EmpID INT NOT NULL,
Name VARCHAR (20) NOT NULL,
Designation VARCHAR(20) NOT NULL,
Salary DECIMAL (12, 2) NOT NULL,
PRIMARY KEY (EmpID)
);
(5) CHECK
The CHECK constraint is used to limit the value range that can be placed
in a column.
For example
CREATE
TABLE parts (
Part_no int PRIMARY KEY,
Description VARCHAR(40),
Price DECIMAL(10, 2) NOT NULL CHECK(cost > 0)
);
(6) IN operator
The IN operator is just similar to OR operator.
It allows to specify multiple values in WHERE clause.
Syntax
SELECT
col1,col2,....
FROM table_name
WHERE column-name IN (value1, value2,...);
Example
Consider following table
Employee

SELECT FROM Employee
WHERE
empID IN (1, 3);
The result will be

Basic Structure of SQL Queries
The basic form of SQL queries is
SELECT-FROM-WHERE. The syntax is as follows:
SELECT[DISTINCT]
target-list
FROMRelation-list
WHEREQualification
• SELECT: This is one of the fundamental query command of SQL. It is similar to
the projection operation of relational algebra. It selects the attributes based
on the condition described by WHERE clause.
• FROM: This clause takes a relation name as an argument from which attributes
are to be selected/projected. In case more than one relation names are given,
this clause corresponds to Cartesian product.
• WHERE: This clause defines predicate or conditions, which must match in order
to qualify the attributes to be projected.
• Relation-list: A list of relation names(tables)
• Target-list: A list of attributes of relations from relation list(tables)
• Qualification:Comparisons of attributes with values or with
other attributes combined using AND, OR and NOT.
• DISTINCT is an optional keyword indicating that the answer should not contain
duplicates. Normally if we write the SQL without DISTINCT operator then it does
not eliminate the duplicates.
Example
SELECT
sname
FROM
Student
WHERE
age>18
• The above query will return names of
all the students from student table where age of each student is greater than
18
Queries on Multiple Relations
Many times it is required to access multiple relations
(tables) to operate on some information. For example consider two tables as
Student and Reserve.

Query: Find the
names of students who have reserved the books with book isbn
Select Student.sname,Reserve.isbn
From Student, Reserve
Where Student.sid=Reserve.sid
Use of SQL Join
The SQL Joins clause is used to combine records from two or
more tables in a database. A JOIN is a means for combining fields from two
tables by using values common to each.
Example:
Consider two tables for using the joins in SQL. Note that cid is common column
in following tables.

1) Inner Join:
• The most important and frequently used of the joins
is the INNER JOIN. They are also known as an EQUIJOIN.
• The INNER JOIN creates a new result
table by combining column values of two alqutul no tables (Table1 and Table2)
based upon the join-predicate.
• The query compares each row of tablel with each row
of Table2 to find all pairs of rows which satisfy the join-predicate.
• When the join-predicate is satisfied, column values for each matched pair of rows of A and B are combined into a result row. It can be represented as:
• Syntax: The basic syntax of the INNER JOIN
is as follows.
SELECT Table1.column1, Table2.column2...
FROM Table1
INNER JOIN Table2
ON
Table1.common_field = Table2.common_field;
• Example: For above given two tables namely Student and City, we can apply inner
join. It will return the record that are matching in both tables using the
common column cid. The query will be
SELECT
*
FROM Student Inner Join City on
Student.cid=City.cid
The result will be
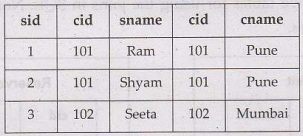
2) Left Join:
• The SQL LEFT JOIN returns all rows from the left
table, even if there are no matches in the right table. This means that if the
ON clause matches 0 (zero) records in the right table; the join will still
return a row in the result, but with NULL in each column from the right table.
• This means that a left join returns all the values
from the left table, plus matched values from the right table or NULL in case
of no matching join predicate.
• It can be represented as –

• Syntax: The basic syntax of a LEFT JOIN is
as follows.
SELECT
SELECT Table1.column1, Table2.column2...
FROM Table1
LEFT JOIN Table2
ON Table1.common field Table2.common field;
• Example: For above given two tables namely Student and City, we can apply Left
join. It will Return all records from the left table, and the matched records
from the right table using the common column cid. The query will be
SELECT
*
FROM Student Left Join City on Student.cid=City.cid
The result will be
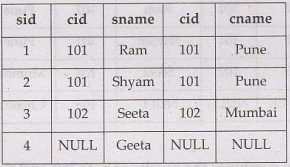
3) Right Join:
• The SQL RIGHT JOIN returns all rows
from the right table, even if there are no matches in the left table.
• This means that if the ON clause matches 0 (zero)
records in the left table; the join will still return a row in the result, but
with NULL in each column from the left table.
• This means that a right join returns all the values
from the right table, plus matched values from the left table or NULL in case
of no matching join predicate.
• It can be represented as follows:
• Syntax: The basic syntax of a RIGHT JOIN is
as follow-
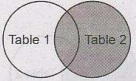
SELECT
Table1.column1, Table2.column2...
FROM Table1
RIGHT JOIN Table2
ON Table1.common_field = Table2.common_field;
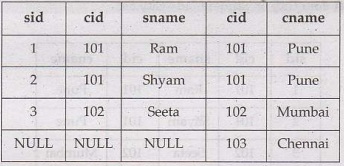
• Example: For above given two tables namely Student and
City, we can apply Rightjoin. It will
return all records from the right table, and the matched records from the left
table using the common column cid. The query will be,
SELECT
*
FROM Student Right Join City on
Student.cid=City.cid
The result will be –
4) Full Join:
• The SQL FULL JOIN combines the
results of both left and right outer joins.
• The joined table will contain all
records from both the tables and fill in NULLS for missing matches on either
side.
• It can be represented as
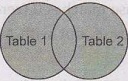
• Syntax: The basic syntax of a FULL JOIN is as follows
SELECT Table1.column1, Table2.column2...
FROM Table1 FULL JOIN Table2 ON Table1.common_field
= Table2.common_field;
The result will be -
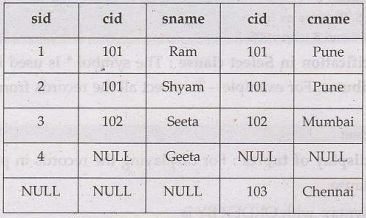
Example: For above
given two tables namely Student and City, we can apply Full join. It will
return returns rows when there is a match in one of the tables using the common
column cid. The query will be -
SELECT
*
FROM Student Full Join City on Student.cid=City.cid
The result will be –
Additional Basic Operations
1) The Rename Operation: The SQL AS is used to assign temporarily a new name to a
table column or table(relation) itself. One reason to rename a relation is to
replace a long relation name with a shortened version that is more convenient
to use elsewhere in the query. For example - "Find the names of students
and isbn of book who reserve the books".
Student

Select S.sname,R.isbn
From Student as S, Reserve as R
Where S.sid=R.sid
In above case we could shorten the names of tables Student
and Reserve as S and R respectively.
Another reason to rename a relation is a case where we wish to compare
tuples in the same relation. We then need to take the Cartesian product of a
relation with itself. For example-
If the query is - Find the names of students who reserve the book of isbn005. Then
the SQL statement will be -
Select S.sname, R.isbn
From Student as S, Reserve as R
Where S.sid-R.sid and S.isbn=005
2) Attribute Specification in Select clause: The symbol * is used in
select clause to denote all attributes. For example - To select all the records
from Student table we can
write
Select* from Student
3) Ordering the display of tuples: For displaying the records in particular order we use order by clause.
The general syntax with ORDER BY is
SELECT column_name(s)
FROM table_name
WHERE condition
ORDER BY column_name(s)
• Example: Consider the
Student table as follows-
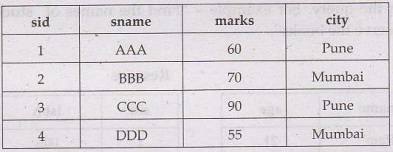
Query: Find the names of students from
highest marks to lowest
Select sname
From Student
Order By marks
We can also use the desc for descending order and asc for
ascending order. For example:
In order to display names of the students in descending order of city -
we can specify
Select sname
From Student
Order by city desc;
(4) Where clause Predicate
(i) The between operator can be used to simplify the where clause which
is used to denote the value be less than or equal to some value and greater
than or equal to some other value. For example - of we want the names of the
students whose marks are between 80 and 90 then SQL statement will be
Select name
From Students
Where marks between 80 and 90;
Similarly we can make use of the comparison operators for various
attributes. For example - If the query is - Find the names of students who
reserve the book of isbn005. Then the SQL statement will be -
Select sname
From Student, Reserve
Where (Student.sid,Reserve.isbn)=(Reserve.sid,005);
(ii) We can use AND, OR and NOT operators in the Where clause. For
filtering the records based on more than one condition, the AND and OR
operators can be used. The NOT operator is used to demonstrate when the
condition is not TRUE.
Consider following sample database - Students database, for applying
AND, OR and NOT operators
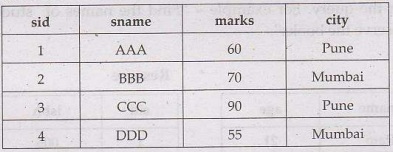
Syntax of AND
SELECT column1, column2, ....
FROM table name
WHERE condition1 AND condition2 AND condition3 ...;
Example: Find the student having name
"AAA" and lives in city "Pune"
SELECT
FROM Students
Where sname='AAA' AND city= 'Pune'
Output

Syntax OR
SELECT column1, column2, ...
FROM table_name
WHERE condition1 OR condition2 OR
condition3 ...;
Example: Find the student having name "AAA" OR lives in city
"Pune"
SELECT
*
FROM Students
Where sname='AAA' OR city='Pune'
Output
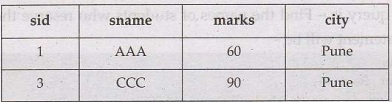
Syntax NOT
SELECT column1, column2, ..
FROM table name
WHERE NOT condition
Example: Find the student who do not have city "Pune"
SELECT
*
FROM Students
Where NOT city='Pune'
Output
Domain and Key Constraint
Domain Constraint
A domain is defined as the set of all unique values
permitted for an attribute. For example, a domain of date is the set of all
possible valid dates, a domain of Integer is all possible whole numbers, and a
domain of day-of-week is Monday, Tuesday Sunday.
This in effect is defining rules for a particular attribute.
If it is determined that an attribute is a date then it should be implemented
in the database to prevent invalid dates being entered.
Domain constraints are user defined data type and we can define them
like this: Domain constraint = Data type + Constraints
The constraints can be specified using NOT NULL / UNIQUE /
PRIMARY KEY / FOREIGN KEY/CHECK/DEFAULT.
For example-
Create domain id_value integer
constraint id_test
check(value > 100); ← cheking if stud_id value is greater than 100
create table student (
stu_id id_value PRIMARY KEY,
stu_name CHAR(30),
stu_age integer
);
Key Constraint
• A key constraint is a statement that
a certain minimal subset of the fields of a relation is a unique identifier for
a tuple.
• For example - Consider the students relation and
the constraint that no two students have the same student id. This IC is an
example of a key constraint.
• The definition of key constraints contain two parts
-
• Two distinct tuples in a legal instance (an instance that satisfies all
Integrity Constraints including the key constraint) cannot have identical
values in all the fields of a key.
• No subset of the set of fields in a key is a unique
identifier for a tuple.
• The first part of the definition
means that, in any legal instance, the values inthe key fields uniquely
identify a tuple in the instance. When specifying a key constraint, the DBA or
user must be sure that this constraint will not prevent them from storing a
'correct' set of tuples. For example, several students may have the same name,
although each student has a unique student id. If the name field is declared to
be a key, the DBMS will not allow the Students relation to contain two tuples
describing different students with the same name.
• The second part of the definition
means, for example, that the set of fields (RollNo, Name} is not a key for
Students, because this set properly contains the key {RollNo}. The set {RollNo,
Name} is an example of a superkey, which is a set of fields that contains a
key.
• The key constraint can be specified using SQL as
follows -
• In SQL, we can declare that a subset of the columns of a table
constitute a key by using the UNIQUE constraint.
• At most one of these candidate keys can be declared to be a
primary key, using the PRIMARY KEY constraint. For example -
CREATE TABLE Student (RollNo integer,
Name CHAR(20),
age integer,
UNIQUE (Name, age),
CONSTRAINT StudentKey PRIMARY KEY(RollNo))
This definition says that RollNo is a Primary key and Combination of
Name and age is also a key.
String Operations
• For string comparisons, we can use the comparison
operators =, <, >,<,>=> with the ordering of strings determined
alphabetically as usual.
• SQL also permits a variety of
functions on character strings such as concatenation suing operator, extracting
substrings, finding length of string, converting strings to upper case(using
function upper(s)) and lowercase(using function lower(s)), removing spaces at
the end of string(using function(trim(s)) and so on.
• Pattern matching can also be
performed on strings using two types of special characters -
• Percent(%): It matches zero, one or multiple characters
• Underscore(_): The _ character matches any single
character.
• The percentage and underscore can be used in
combinations.
• Patterns are case sensitive. That means upper case
characters do not match lowercase characters or vice versa.
• For
instance:
• 'Data%' matches any string beginning with "Data", For instance
it could be with a blen "Database",
"DataMining","DataStructure"
• ' _ _ _' matches any string of exactly three characters.
• ' _ _ _'%'matches any string of at least length 3
characters.
• The LIKE clause can be used in WHERE clause to
search for specific patterns.
• For example - Consider following
Employee Database
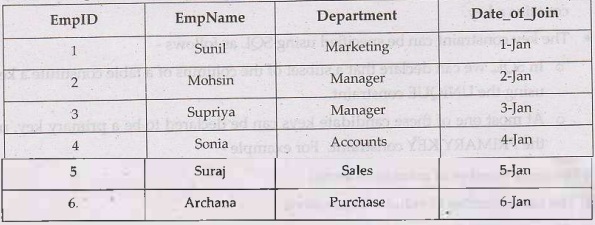
(1) Find all the employee with EmpName
starting with "s"
SQL Statement:
SELECT FROM Employee
WHERE
EmpName LIKE 's%'
Output
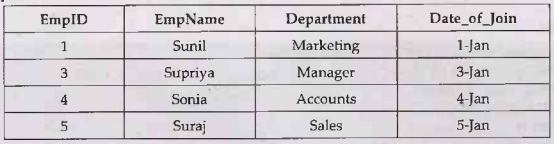
(2) Find the names of employee whose name
begin with S and end with a
SQL Statement:
SELECT EmpName FROM Employee
WHERE EmpName LIKE 'S%a'
Output

(3) Find the names of employee whose name
begin with S and followed by exactly four characters
SELECT EmpName FROM Employee
WHERE
EmpName LIKE 'S_ _ _’
Output

Set Operations
1) UNION: To use this
UNION clause, each SELECT statement must have
i) The same number of columns selected
ii) The same number of column expressions
iii) The same data type and
iv) Have them in the same order
This clause is used to combine two tables using UNION operator. It
replaces the OR operator in the query. The union operator eliminates duplicate
while the union all query will retain the duplicates.
Syntax
The basic syntax of a UNION clause is as follows -
SELECT column1 [, column2]
FROM table1 [, table2 ]
[WHERE condition]
UNION
SELECT column1 [, column2 ]
FROM table1 [, table2 ].
[WHERE condition]
Here, the given condition could be any given expression
based on your requirement.
Consider Following relations –

Example: Find the names of the students who
have reserved the 'DBMS' book or 'OS' Book
The query can then be written by considering the Student, Reserve and
Book table as
SELECT S.sname
FROM Student S, Reserve R, Book B
WHERE S.sid-R.sid AND R.isbn=B.isbn AND
B.bname='DBMS'
UNION
SELECT S.sname
FROM Student S, Reserve R, Book B
WHERE
S.sid-R.sid AND R.isbn=B.isbn AND B.bname='OS'
2) INTERSECT: The common entries between the two tables can be
represented with the help of Intersect operator. It replaces the AND operator
in the query.
Syntax
The basic syntax of a
INTERSECT clause is as follows --
SELECT column1 [, column2]
FROM table1 [, table2 ]
[WHERE condition]
INTERSECT
SELECT column1 [, column2]
FROM table1 [, table2 ]
[WHERE condition]
Example: Find the students who have reserved
both the 'DBMS' book and 'OS' Book
The query can then be written by considering the Student, Reserve and
Book table as
SELECT S.sid, S.sname
FROM Student S, Reserve R, Book B
WHERE S.sid-R.sid AND R.isbn=B.isbn AND
B.bname='DBMS'
INTERSECT
SELECT S.sname
FROM Student S, Reserve R, Book B
WHERE S.sid-R.sid AND R.isbn=B.isbn AND
B.bname='OS'
3) EXCEPT: The EXCEPT clause is used to represent the set-difference in the query.
This query is used to represent the entries that are present in one table and
not in other.
Syntax:
The basic syntax of a EXCEPT clause is as follows -
SELECT column1 [, column2 |
FROM table1 [, table2 ]
[WHERE condition]
EXCEPT
SELECT column1 [, column2]
FROM table1 [, table2]
[WHERE condition]
Example:
Find the students who have reserved both the 'DBMS' book but not reserved 'OS'
Book
The query can then be written by considering the Student, Reserve and
Book table as
SELECT S.sid, S.sname
FROM Student S, Reserve R, Book B
WHERE S.sid=R.sid AND R.isbn=B.isbn AND
B.bname='DBMS'
EXCEPT
SELECT S.sname
FROM Student S, Reserve R, Book B
WHERE S.sid=R.sid AND R.isbn=B.isbn AND
B.bname='OS'
Aggregate Functions
• An aggregate function allows you to
perform a calculation on a set of values to return a single scalar value.
• SQL offers five built-in aggregate functions:
1. Average: avg
2. Minimum: min
3. Maximum : max
4. Total: sum
5. Count:
1. Basic Aggregation
The aggregate functions that accept an expression parameter can be
modified by the keywords DISTINCT or ALL. If neither is specified, the result
is the same as if ALL were specified.

Syntax of all the Aggregate Functions
AVG([ DISTINCT | ALL ] expression)
COUNT(*)
COUNT([ DISTINCT | ALL | expression)
MAX( | DISTINCT | ALL ] expression)
MIN([ DISTINCT | ALL ] expression)
SUM([DISTINCT | ALL ] expression)
• The avg function is used to compute average value.
For example - To compute average marks of the students we can use t
SQL Statement
SELECT
AVG(marks)
FROM Students
• The Count function is used to count the total
number of values in the specified field. It works on both numeric and
non-numeric data type. COUNT (*) is a special implementation of the COUNT
function that returns the count of all the rows in a specified table. COUNT (*)
also considers Nulls and duplicates. For example Consider following table
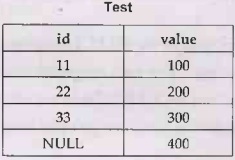
SQL Statement
SELECT
COUNT(*)
FROM Test
Output
4
SELECT
COUNT(ALL id)
FROM
Test
Output
3
• The min function is used to get the
minimum value from the specified column. For example - Consider the above
created Test table
SQL Statement
SELECT
Min(value)
FROM Test
Output
100
• The max function is used to get the maximum value
from the specified column. For example - - Consider the above created Test
table
SQL Statement
SELECT
Max(value)
FROM
Test
Output
400
• The sum function is used to get
total sum value from the specified column. For example - Consider the above
created Test table
SOL Statement
SELECT
sum(value)
FROM
Test
Output
1000
2. Use of Group By and Having Clause
(i) Group By:
• The GROUP BY clause is a SQL command that is used
to group rows that have the same values.
• The GROUP BY clause is used in the
SELECT statement.
• Optionally it is used in conjunction with aggregate
functions.
• The queries that contain the GROUP BY clause are
called grouped queries
• This query returns a single row for
every grouped item.
• Syntax :
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
The general syntax with ORDER BY is
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column name(s)
ORDER BY column_name(s)
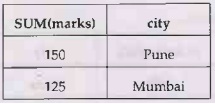
Example : Consider the Student table as follows-
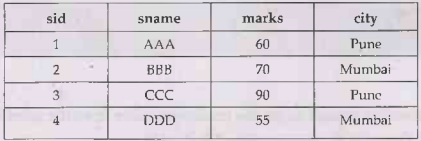
Query: Find the total marks of each
student in each city
SELECT
SUM(marks), city
FROM Student
GROUP BY city
Output
(ii) Having:
• HAVING filters records that work on summarized
GROUP BY results.
• HAVING applies to summarized group records, whereas
WHERE applies to been individual records.
• Only the groups that meet the HAVING
criteria will be returned.
• HAVING requires that a GROUP BY clause is present.
• WHERE and HAVING can be in the same query.
• Syntax:
SELECT column-names
FROM table-name
WHERE condition
GROUP BY column-names
HAVING condition
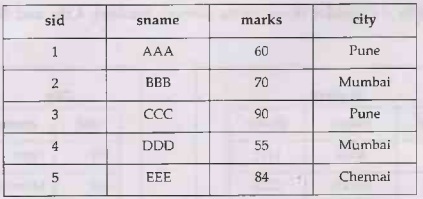
Example: Consider the Student table as follows –
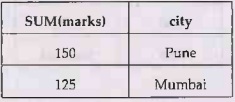
Query: Find the total marks of each student in the city named 'Pune' and
'Mumbai'
only
SELECT
SUM(marks), city
FROM Student
GROUP BY
city
HAVING city IN('Pune', 'Mumbai')
Output
• The result will be as follows-
Nested Queries
In nested queries, a query is written inside a query. The
result of inner query is used in
execution of outer query.
There are two types of nested queries:
i) Independent Query:
• In independent nested queries, query
execution starts from innermost query to outermost queries.
• The execution of inner query is
independent of outer query, but the result of inner query is used in execution
of outer query.
• Various operators like IN, NOT IN,
ANY, ALL etc are used in writing independent nested queries.
• For example - Consider three tables namely Student,
City and Student_City as follows-
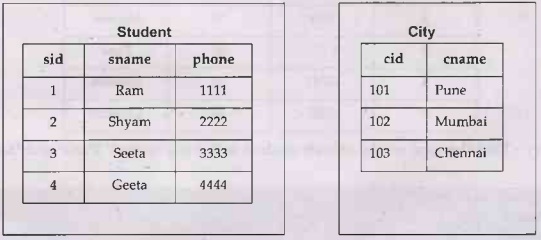
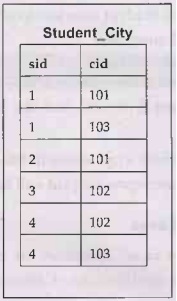
• Example 1 - If we want to find out sid who
live in city 'Pune' or 'Chennai'. We can then write independent nested query
using IN operator. Here we can use the IN operator allows you to specify
multiple values in a WHERE clause. The IN operator is a shorthand for multiple
OR conditions.
Step 1: Find cid for cname='Pune' or
'Chennai'. The query will be
SELECT cid
FROM City
WHERE cname='Pune' or 'Chennai'
Step 2: Using cid obtained in step 1 we can
find the sid. The query will be
SELECT sid
FROM Student_City
WHERE cid IN
(SELECT cid FROM City WHERE cname='Pune' or
cname='Chennai')
The inner query will return a set with members 101 and 103
and outer query will return those sid for which cid is equal to any member of
set (101 and 103 in this case). So, it will return 1, 2 and 4.
Example
2: If we want to find out
sname who live in city 'Pune' or 'Chennai'.
SELECT sname FROM Student WHERE sid IN
(SELECT sid FROM Student City WHERE cid IN
(SELECT cid FROM City WHERE cname='Pune' or
cname='Chennai'))
ii) Co-related Query:
In co-related nested queries, the output of inner query depends on the
row which is being currently executed in outer query. For example
If we want to find out sname of Student who live in city with cid as
101, it can be done with the help of co-related nested query as:
SELECT sname FROM Student S WHERE EXISTS
(SELECT * FROM Student_City SC WHERE S.sid=SC.sid
and SC.cid=101)
Here For each row of Student S, it will find
the rows from Student_City where S.sid SC.sid and SC.cid=101.
If for a sid from Student S, atleast a row exists in Student
City SC with cid=101, then inner query will return true and corresponding sid
will be returned as output.
Modification of Databases
The modification of database is an operation for making
changes in the existing databases. Various operations of modification of
database are insertion, deletion and updation of databases.
1. Deletion: The delete command is used to delete the existing record.
Syntax
delete from table_name
where condition;
Example
delete from student
where RollNo=10
2. Insertion: The insert command is used to insert data into
the table. There are two syntaxes of inserting data into SQL
Syntax
(i) Insert into table_name (column1, column2,
column3, ...)
values (value1, value2, value3, ...);
(ii) insert into table_name
values (value1, value2, value3, ...);
Example
(i) insert into Student (RollNo,Name, Makrs) values
(101, 'AAA',56.45)
(ii) insert into Student values(101,'AAA',56.45)
3. Update: The update
statement is used to modify the existing records in the table.
update table_name
set column1-value1, column2=value2,...
where condition;
Example :
Delete student
Set Name='WWW'
where Roll No=101
Review Questions
1. Explain aggregate functions in SQL with example. AU: May-18, Marks 13
2. Write DDL, DML, DCL commands for the students database. AU: Dec.-17, Marks 7
3. Explain about SQL fundamentals. AU: May-16, Marks 8
4. Explain about Data Definition Language. AU: May-16, Marks 8
5. Explain the six clauses in the syntax of SQL query and show what type of constructs can be specified in each of the six clauses. Which of the six clauses are required and which are optional? AU: Dec.-15, Marks 16
6. Explain- DDL and DML. AU: Dec.-14, Marks 8
Database Management System: Unit I: Relational Databases : Tag: : Relational Databases - Database Management System - SQL Fundamentals
Related Topics
Related Subjects

Database Management System
CS3492 4th Semester CSE Dept | 2021 Regulation | 4th Semester CSE Dept 2021 Regulation