Digital Principles and Computer Organization: Unit IV: Processor
Two marks Questions with Answers
Processor - Digital Principles and Computer Organization
The complete instruction cycle involves three operations: Instruction fetching, opcode decoding and instruction execution.
Two Marks Questions with
Answers
7.1 Instruction Execution
Q.1 List the operations involved in
instruction cycle.
Ans.: The complete
instruction cycle involves three operations: Instruction fetching, opcode
decoding and instruction execution.
Q.2 What is instruction fetch cycle ?
Ans.: In this cycle,
the instruction is fetched from the memory location whose address is in the PC.
This instruction is placed in the Instruction Register (IR) in the processor.
Q.3 What is instruction decode cycle ?
Ans.: In this cycle,
the opcode of the instruction stored in the instruction register is
decoded/examined to determine which operation is to be performed.
Q.4 What is instruction execution cycle
?
Ans.: In this cycle,
the specified operation is performed by the processor. This often involves
fetching operands from the memory or from processor registers, performing an
arithmetic or logical operation and storing the result in the destination
location.
During the instruction execution, PC
contents are incremented to point to the next instruction. After completion of
execution of the current instruction, the PC contains the address of the next
instruction and a new instruction fetch cycle can begin.
7.3 Building a Datapath
Q.5 Define datapath.AU May-14, 18,
Dec.-16
Ans.: Datapath is an
unit used to operate on or hold data within a processor. Its elements include
the instruction and data memories, the register file, the ALU and adders.
Q.6 Define register file.
Ans.: All general
purpose registers are combined into a single block called the register file.
Q.7 Draw the datapath segment for
arithmetic-logic instructions.
Ans.: Refer Fig.
7.3.2.

Q.8 Draw the datapath segment for
computation of branch target address.
Ans.: Refer Fig.
7.3.4.
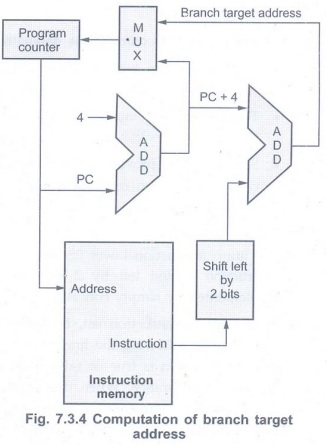
Q.9 What do you mean by delayed branch ?
Ans.:Refer last
paragraph of section 7.3.3.
In the MIPS instruction set, branches are delayed, meaning that the instruction immediately following the branch is always executed, independent of whether the branch condition is true or false. When the condition is false, the execution looks like a normal branch. When the condition is true, a delayed branch first executes the instruction immediately following the branch in sequential instruction order before jumping to the specified branch target address.
7.4 Design a Control Unit
Q.10 State the advantages of using multiple
levels of decoding.
Ans.: It reduces the
size of the main control unit.
Use of several smaller control units may
also potentially increase the speed of the control unit.
Q.11 Draw the format of R-type and
branch instructions.
Ans.:Refer Fig.
7.4.1.

Q.12 Draw the format of load or store
instruction.
Ans.:Refer Fig. 7.4.1.
Q.13 Draw the format of jump instruction.
Ans.:Refer Fig.
7.4.7.

Q.14 State reasons for not using single
cycle implementation.
Ans.: Refer section
7.4.3.6.
1. It is inefficient. Because the longest possible path in the processor determines the clock cycle. Remember that the clock cycle must have the same length for every instruction in single-cycle design.
2. The overall performance of a single-cycle implementation is likely to be poor, since the clock cycle is too long.
3. The penalty for using the single-cycle design with a fixed clock cycle is significant. Single-cycle designs for floating-point unit or an instruction set with more complex instructions do not work well at all.
4. It do not improve the worst-case cycle time. Thus it violates the great idea of making the common case fast.
Ans.: The
microroutines for all instructions in the instruction set of a computer are
stored in a special memory called the control store.
7.5 Hardwired Control
Q.16 State the advantages of hardwired
control unit.
Ans.:•Hardwired
control unit is fast because control signals are generated by combinational
circuits.
• The delay in generation of control
signals depends upon the number of gates.
• It has greater chip area efficiency
since its uses less area on-chip.
Q.17 State the disadvantages of
hardwired control unit.
Ans.: • More the
control signals required by CPU; more complex will be the design of control
unit.
• Modifications in control signal are
very difficult. That means it requires rearranging of wires in the hardware
circuit.
• It is difficult to correct mistake in
original design or adding new feature in existing design of control unit.
7.6 Microprogrammed Control
Q.18 What is microprogramming ?
Ans.: Microprogramming
is a method of control unit design in which the control signal selection and
sequencing information is stored in a ROM or RAM called a control memory CM.
Q.19 What is control memory ?
Ans.: A memory that
is part of a control unit is referred to as a control memory. It stores the
sequences of micro-operations to be performed to execute microinstructions.
Q.20 Give full form of CAR.
Ans.: CAR stands for
Control Address Register.
Q.21 What is microprogram sequencing ?
Ans.: Determining the
address of the next microinstruction to be executed using microprogram
sequencer is called microprogram sequencing.
Q.22 What is address sequencing ?
Ans.:Each computer
instruction has its own microprogram routine in control memory to generate the
micro-operations that execute the instruction. To execute a particular computer
instruction, accessing a corresponding microinstruction routine, sequencing the
microinstructions within the routine and if necessary branching from one
routine to another is known as address sequencing.
Q.23 What is microinstruction ?
Ans.: Each word in
the control memory is a microinstruction which specifies the control signals to
be activated to perform one or more micro-operations.
Q.24 What is microcode ?
Ans.: The translation
of symbolic microprogram to binary produces a binary microprogram called
microcode.
Q.25 What is microprogram ?
Ans.: A sequence of
one or more micro-operations designed to perform specific operation, such as
addition, multiplication is called a microprogram.
Q.26 What is pipeline register?
Ans.: The control
data register holds the present microinstruction while the next address is
computed and read from memory. This data register is sometimes called a
pipeline register. It allows the execution of micro-operations specified by the
control word and the generation of the next microinstruction simultaneously.
7.8 Pipelining
Q.27 Define pipelining.
Ans.: Pipelining is a
technique of decomposing a sequential process into sub operations with each sub
process being executed in a special dedicated segment that operates
concurrently with all other segments.
Q.28 Mention the various types of
pipelining.
Ans.: Types of pipelining are: Instruction pipelining and arithmetic pipelining
Q.29 What
is instruction pipelining ?
Ans.: Performing
fetch, decodeand execute cycles forseveralinstructionssimultaneously to reduce
overall processing time is referred to as instruction pipelining.
Q.30 List the four stages in the
instruction pipelining.
OR Mention the various phases in
executing an instruction. AU Dec.-17
Ans.: The four stages
in the instruction pipelining are :
S1 - Fetch (F): Read
instruction from the memory.
S2- Decode (D): Decode the
opcode and fetch source operand (s) if necessary.
S3- Execute (E): Perform the
operation specified by the instruction.
S4-Store (S): Store the
result in the destination.
Q.31 What is the ideal speed-up expected in a pipelined architecture with 'n' stages? Justify your answer.
(Refer example 7.8.4) AU: May-07
• The performance of pipelined processor depends on whether the functional units are pipelined and whether they are multiple execution units to allow all possible combination of instructions in the pipeline. If for some combination, pipeline has to be stalled to avoid the resource conflicts then there is a structural hazard.
• In other words, we can say that when two instructions require the use of a given hardware resource at the same time, the structural hazard occurs.
• The most common case in which this hazard may arise is in access to memory. One instruction may need to access memory for storage of the result while another instruction or operand needed is being fetched. If instructions and data reside in the same cache unit, only one instruction can proceed and the other instruction is delayed. To avoid such type of structural hazards many processors use separate caches for instruction and data.
Q.32 What is meant by hazard in
pipelining?AU: May-13, 17
Ans.: Any reason that
causes the pipeline to stall is called a hazard.
Q.33 List the different types of
hazards.
Ans.: The different
types of instruction hazards are :
1. Structural hazards.
2. Data or Data dependent hazards.
3. Instruction or Control hazards.
Q.34 What is structural hazard ?AU:
May-14
Ans.: The hazard that
exist because of conflicts due to insufficient resources when even with all
possible combination, it may not be possible to overlap the operation is called
structural hazard.
Q.35 What is instruction or control
hazard?AU: May-12, 13
Ans.: The hazard due
to pipelining branch and other instructions that change the contents of program
counter is called instruction or control hazard.
Q.36 What is pipeline scheduling?
Ans.: Rather than
allowing the pipeline to stall, the compiler can rearrange instructions to
avoid data hazard. It is called pipeline scheduling.
Q.37 What is delayed load and delayed
slot ?
Ans.: A load which
requires that the following instruction do not use its result is said to be
delayed load and the pipeline slot after load instruction is called delayed
slot.
Q.38 How addressing modes affect the
instruction pipelining?AU : May-14Ans.: Degradation of
performance is an instruction pipeline may be due to address dependency where
operand address cannot be calculated without available information needed by addressing
mode for e.g. an instructions with register indirect mode cannot proceed to
fetch the operand if the previous instructions is loading the address into the
register. Hence operand access is delayed degrading the performance of
pipeline.
Q.39 How compiler is used in pipelining
?
Ans.: A compiler
translates a high level language program into a sequence of machine
instructions. The number of cycles required to execute program is dependent not
only on the choice of instruction, but also on the order in which they appear
in the program. The compiler may rearrange program instruction to achieve
better performance of course, such changes must not affect of the result of the
computation.
Q.40 What is loop buffer ?
Ans.: A loop buffer
is a small very high speed memory. It is used to store recently prefetched
instructions in sequence. If conditional branch is valid, the hardware first
checks whether the branch target is within the loop buffer. If so, the next
instructions are fetched from the buffer, instead of memory avoiding memory
access.
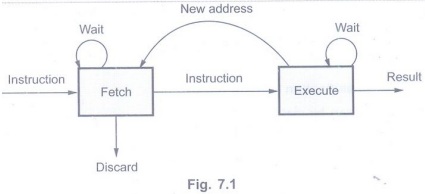
Q.41 Draw the structure of two stage
instruction pipe line. AU:
Dec.-07
Ans.: The Fig. 7.1
shows the structure of two stage instruction pipe line.
Q.42 What would be the effect, if we
increase the number of pipelining stages?
AU: Dec.-11
Ans.: As the number
of pipeline stages increases, the probability of the pipeline being stalled
also increases because more instructions are being executed concurrently. Thus,
dependencies between instructions that are far apart may still cause the
pipeline to stall.
As the number of pipeline stages
increase, the branch penalties may become more significant.
Q.43 What are the advantages of
pipelining ?AU: May-16
Ans.: 1. The
instruction cycle time of the processor is reduced increasing, instruction
throughput.
2. Increase in pipeline stages increase
number of instructions that can be processed at once which reduces delay
between completed instructions.
Q.44 What is meant by pipeline bubble/
pipeline stall ?AU: Dec.-16
Ans.: Pipeline bubble
or pipeline stall is a delay in execution of an instruction in an instruction
pipeline in order to resolve a hazard.
Q.45 What is datapath element ?AU:
Dec.-16
Ans.: Datapath element
is unit used to operate on or hold data within a processor. In the MIPS
implementation, the datapath elements include the instruction and data
memories, the register file, the ALU, and adders.
Q.46 Name the control signals required to perform arithmetic operation. AU: May - 17
Ans.: Control signals
RegDst, RegWrite and ALUop1 are required to perform arithmetic operation.
7.10 Handling Data Hazards
Q.47 What is data hazard in pipelining? What are the solutions ? AU: Dec.-07, May-12, 13
Ans.: When either the
source or the destination operands of an instruction are not available at the
time expected in the pipeline and as a result pipeline is stalled, we say such
a situation is a data hazard.
1. The easiest way to handle data
hazards is to stall the pipeline.
2. The second simple hardware technique
which can handle data hazard is called forwarding or register by passing.
Q.48 What are the classification of data
hazards ?AU: May-17
Ans.: The data hazard
can be classified as,
1. RAW (read after write) hazard
2. WAW (write after write) hazard
3. WAR (write after read) hazard
Q.49 What is the use of condition code
register?
Ans.: The conditional
branch instruction checks the condition code flags to decide the flow of
program execution.
Q.50 What do you mean by out-of order
execution ?
Ans.: The dispatch
unit dispatches the instructions in the order in which they appear in the
program. But their execution may be completed in the different order because of
data dependency among the instructions. Such situation is called out-of order
execution.
Q.51 What is instruction throughput ?
Ans.: The instruction
throughput is the number of instructions executed per second. For sequential
execution, it is given by,
where R is a clock rate measured in
clocks per second and S is the average number of steps needed to execute one
machine instruction.
7.11 Handling Control Hazards
Q.52 Why is branch prediction algorithm
needed ? AU: May-12
Ans.: Branch
prediction algorithm is needed to reduce the branch penalty.
Q.53 List commonly used branch prediction
techniques.
Ans.:The commonly
used branch prediction techniques are:
• Predict Never Taken
• Predict Always Taken
• Predict By Opcode
•Taken/Not Taken Switch
• Branch History Table.
Q.54 Name the two types of branch
prediction strategies.
Ans.: The two types
of branch prediction strategies are:
• Static branch strategy
• Dynamic branch strategy.
Q.55 What is branch target / prediction
buffer ? AU: May-15
Ans.: The buffer in
which the recent branch information is stored is called branch target buffer.
Q.56 What is branch folding ?
Ans.: The instruction
fetch unit has executed the branch instruction concurrently with the execution
of other instructions. This technique is referred to as branch folding.
Q.57 What is delayed branching?
Ans.: A technique
called delayed branching can minimize the penalty incurred as a result of
conditional branch instructions. The idea is simple. The instructions in the
delay slots are always fetched. Therefore, we would like to arrange for them to
be fully executed whether or not the branch is taken. The objective is to be
able to place useful instructions in these slots. If no useful instructions can
be placed in the delay slots, these slots must be filled with NOP instructions.
Q.58 What is meant by speculative
execution ? AU: May-12
Ans.: Speculative
execution means that instructions are executed before the processor is certain
that they are in the correct execution sequence. Hence, care must be taken that
no processor registers or memory locations are updated until it is confirmed
that these instructions should indeed be executed. If the branch decision
indicates otherwise, the instructions and all their associated data in the
execution units must be purged, and the correct instructions fetched and
executed.
Q.59 What is called static and dynamic
branch prediction ?
OR Differentiate between the static and
dynamic techniques. AU: May-13
Ans.: The branch
prediction decision is always the same every time a given instruction is
executed. Any approach that has this characteristic is called static branch
prediction. Another approach in which the prediction decision may change
depending on execution history is called dynamic branch prediction.
Q.60 What is the role of cache in
pipelining? AU: Dec.-11.
Digital Principles and Computer Organization: Unit IV: Processor : Tag: : Processor - Digital Principles and Computer Organization - Two marks Questions with Answers
Related Topics
Related Subjects

Digital Principles and Computer Organization
CS3351 3rd Semester CSE Dept | 2021 Regulation | 3rd Semester CSE Dept 2021 Regulation