Artificial Intelligence and Machine Learning: Unit III: Supervised Learning
Random Forests
Supervised Learning - Artificial Intelligence and Machine Learning
Random forest is a famous system learning set of rules that belongs to the supervised getting to know method. It may be used for both classification and regression issues in ML.
Random
Forests
•
Random forest is a famous system learning set of
rules that belongs to the supervised getting to know method. It may be used for
both classification and regression issues in ML. It is based totally on the
concept of ensemble studying, that's a process of combining multiple
classifiers to solve a complex problem and to enhance the overall performance
of the model.
•
As the call indicates, "Random forest is a
classifier that incorporates some of choice timber on diverse subsets of the
given dataset and takes the average to improve the predictive accuracy of that dataset."
Instead of relying on one decision tree, the random forest takes the prediction
from each tree and primarily based on most of the people's votes of
predictions, and it predicts the very last output.
•
The more wider variety of trees within the forest
results in better accuracy and prevents the hassle of overfitting.
How Does Random Forest Algorithm Work?
•
Random forest works in two-section first is to create
the random woodland by combining N selection trees and second is to make
predictions for each tree created inside the first segment.
•
The working technique may be explained within the
below steps and diagram:
Step
1: Select random K statistics points from the schooling set.
Step
2: Build the selection trees associated with the selected information
points (Subsets).
Step
3: Choose the wide variety N for selection trees which we want to
build.
Step
4: Repeat step 1 and 2.
Step
5: For new factors, locate the predictions of each choice tree and
assign the new records factors to the category that wins most people's votes.
•
The working of the set of rules may be higher
understood by the underneath example:
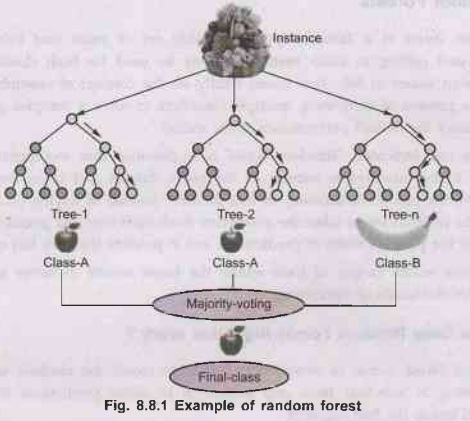
•
Example: Suppose there may be a dataset that includes
more than one fruit photo. So, this dataset is given to the random wooded area
classifier. The dataset is divided into subsets and given to every decision
tree. During the training section, each decision tree produces a prediction end
result and while a brand new statistics point occurs, then primarily based on
the majority of consequences, the random forest classifier predicts the final
decision. Consider the underneath picture:
Applications of Random Forest
There
are specifically 4 sectors where random forest normally used:
SAT
1.
Banking: Banking zone in general uses this
algorithm for the identification of loan danger.
2.
Medicine: With the assistance of this set of
rules, disorder traits and risks of the disorder may be recognized.
3.
Land use: We can perceive the areas of comparable
land use with the aid of this algorithm.
4.
Marketing: Marketing tendencies can be recognized
by the usage of this algorithm.
Advantages of Random Forest
Random
forest is able to appearing both classification and regression
responsibilities.
•
It is capable of managing large datasets with high
dimensionality.
• It enhances the accuracy of the version and forestalls the overfitting trouble.
Disadvantages of Random Forest
Artificial Intelligence and Machine Learning: Unit III: Supervised Learning : Tag: : Supervised Learning - Artificial Intelligence and Machine Learning - Random Forests
Related Topics
Related Subjects

Artificial Intelligence and Machine Learning
CS3491 4th Semester CSE/ECE Dept | 2021 Regulation | 4th Semester CSE/ECE Dept 2021 Regulation