Database Management System: Unit IV: Implementation Techniques
RAID
Implementation Techniques - Database Management System
RAID stands for Redundant Array of Independent Disks. This is a technology in which multiple secondary disks are connected together to increase the performance, data redundancy or both.
Unit: IV: Implementation Techniques
Syllabus
RAID-File Organization -
Organization of Records in Files - Data dictionary Storage - Column Oriented
Storage - Indexing and Hashing - Ordered Indices - B+ tree Index Files - B tree
Index Files - Static Hashing - Dynamic Hashing - Query Processing Overview -
Algorithms for Selection, Sorting and join operations - Query optimization
using Heuristics - Cost Estimation.
Part 1: File Organization and Indexing
RAID
• RAID stands for Redundant Array of
Independent Disks. This is a technology in which multiple secondary disks are
connected together to increase the performance, data redundancy or both.
• For achieving the data redundancy -
in case of disk failure, if the same data is also backed up onto another disk,
we can retrieve the data and go on with the operation.
• It consists of an array of disks in
which multiple disks are connected to achieve different goals.
• The main advantage of RAID, is the fact that, to
the operating system the array of disks can be presented as a single disk.
Need for RAID
• RAID is a technology that
is used to increase the performance.
• It is used for increased
reliability of data storage.
• An array of multiple disks accessed in parallel
will give greater throughput than a single disk.
• With multiple disks and a suitable
redundancy scheme, your system can stay up and running when a disk fails, and
even while the replacement disk is being installed and its data restored.
Features
(1) RAID is a technology that contains the set of physical
disk drives.
(2) In this technology, the operating system views the
separate disks as a single logical disk.
(3) The data is distributed across the physical drives of the array.
(4) In case of disk failure, the parity information can be helped to
recover the data.
RAID Levels
Level: RAID 0
• In this level, data is broken down
into blocks and these blocks are stored across all the disks.
• Thus striped array of disks is
implemented in this level. For instance in the following figure blocks "A
B" form a stripe.
• There is no duplication of data in this level so
once a block is lost then there is no int lovol diri way recover it.
• The main priority of this
level is performance and not the reliability.

Level: RAID 1
• This level makes use of mirroring.
That means all data in the drive is duplicated to another drive.
• This level provides 100% redundancy
in case of failure.
• Only half space of the drive is used
to store the data. The other half of drive is just a mirror to the already
stored data.
• The main advantage of this level is fault
tolerance. If some disk fails then the other automatically takes care of lost
data.

Level: RAID 2
• This level makes use of
mirroring as well as stores Error Correcting Codes (ECC) for its data striped
on different disks.
• The data is stored in separate set of disks and ECC
is stored another set of disks.
• This level has a complex structure and high cost.
Hence it is not used commercially.

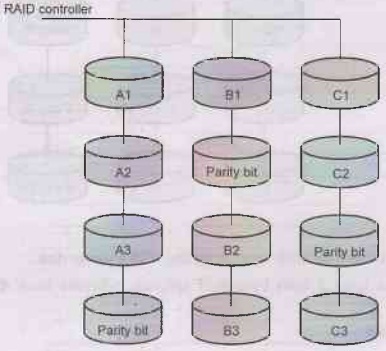
Level: RAID 3
• This level consists of byte-level
stripping with dedicated parity. In this level, the parity information is
stored for each disk section and written to a dedicated. parity drive.
• We can detect single errors with a parity bit.
Parity is a technique that checks whether data has been lost or written over
when it is moved from one place in storage to another.
• In case of disk failure, the parity
disk is accessed and data is reconstructed from the remaining devices. Once the
failed disk is replaced, the missing data can be restored on the new disk.
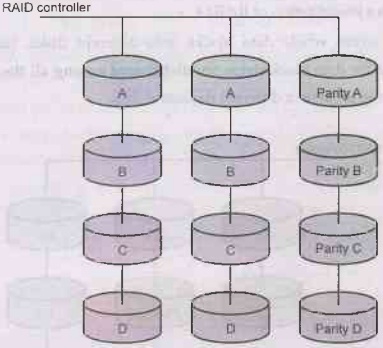
Level: RAID 4
• RAID 4 consists of block-level stripping with a
parity disk.
• Note that level 3 uses byte-level striping, whereas
level 4 uses block-level striping.
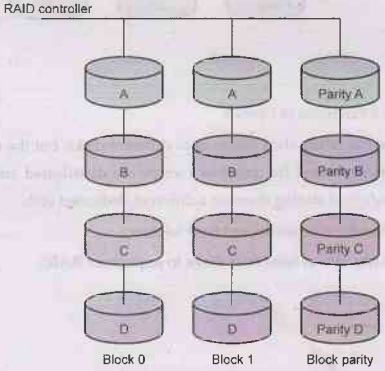
Level: RAID 5
• RAID 5 is a modification of RAID 4.
• RAID 5 writes whole data blocks onto
different disks, but the parity bits generated for data block stripe are
distributed among all the data disks rather than storing them on a different
dedicated disk.
Level:
RAID 6
• RAID 6 is a extension of Level 5
• RAID 6 writes whole data blocks onto different
disks, but the two independent parity bits generated for data block stripe are
distributed among all the data disks rather than storing them on a different
dedicated disk.
• Two parities provide additional fault tolerance.
• This level requires at least four
disks to implement RAID.

The factors to be taken into account in choosing a RAID
level are :
Monetary cost of extra disk-storage requirements.
1. Performance requirements in terms of number of I/O operations.
2. Performance when a disk has failed.
3. Performance during rebuild
Review Questions
1.
Explain what a RAID system is? How does it improve performance and reliability.
Discuss the level 3 and level 4 of RAID.
AU: May-17, Marks (3+4+6)
2. Explain the concept of RAID. AU: Dec.-16, Marks 6, Dec.-14, Marks 8
3. Briefly explain RAID and RAID levels. AU: Dec.-06, Marks 10, Dec.-13, May-15, 16, Marks
16
4.What is
RAID? List the different levels in RAID technology and explain its features.
5. What is RAID? Briefly discuss about RAID. AU: May-19, Marks 13
6. Explain various levels of RAID Systems.
Database Management System: Unit IV: Implementation Techniques : Tag: : Implementation Techniques - Database Management System - RAID
Related Topics
Related Subjects

Database Management System
CS3492 4th Semester CSE Dept | 2021 Regulation | 4th Semester CSE Dept 2021 Regulation