Foundation of Data Science: Unit IV: Python Libraries for Data Wrangling
Pivot Tables
Python Libraries for Data Wrangling
A pivot table is a similar operation that is commonly seen in spreadsheets and other programs that operate on tabular data.
Pivot Tables
• A
pivot table is a similar operation that is commonly seen in spreadsheets and other
programs that operate on tabular data. The pivot table takes simple column-wise
data as input, and groups the entries into a two-dimensional table that
provides a multidimensional summarization of the data.
• A
pivot table is a table of statistics that helps summarize the data of a larger
table by "pivoting" that data. Pandas gives access to creating pivot
tables in Python using the .pivot_table() function.
• The
syntax of the .pivot_table() function:
import
pandas as pd
pd.pivot_table(
data=,
values=None,
index=None,
columns=None,
aggfunc='mean',
fill_value
=None,
margins=False,
dropna=True,
margins_name='All',
observed=False,
sort=True
)
• To use
the pivot method in Pandas, we need to specify three parameters:
1. Index: Which column should be used
to identify and order the rows vertically.
2. Columns: Which column should be used
to create the new columns in reshaped DataFrame. Each unique value in the
column stated here will create a column in new DataFrame.
3. Values: Which column(s) should be
used to fill the values in the cells of DataFrame.
• Import modules:
import
pandas as pd
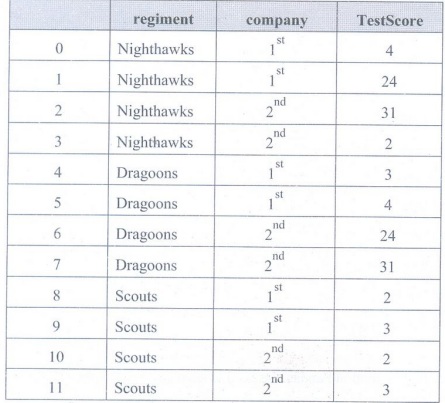
Create dataframe :
raw_data={'regiment':
['Nighthawks', 'Nighthawks', 'Nighthawks', 'Nighthawks','Dragoons','
Dragoons', 'Dragoons', 'Dragoons', 'Scouts',
'Scouts', 'Scouts', 'Scouts'],
'company':
['1st', '1st', '2nd', '2nd', '1st', '1st', '2nd', '2nd', '1st', '1st',
'2nd','2nd'],
'TestScore':
[4,24,31,2,3,4,24,31,2,3,2,3]}
df
pd.DataFrame(raw_data, columns=['regiment','company', 'TestScore'])
df
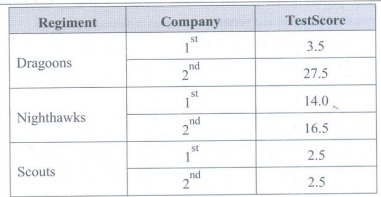
• Create
a pivot table of group means, by company and regiment
pd.pivot_table(df,index=['regiment','company'],
aggfunc='mean')
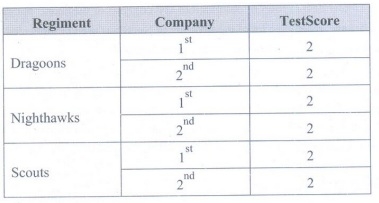
• Create
a pivot table of group score counts, by company and regiment
df.pivot_table(index=['regiment', 'company'],
aggfunc='count')
Foundation of Data Science: Unit IV: Python Libraries for Data Wrangling : Tag: : Python Libraries for Data Wrangling - Pivot Tables
Related Topics
Related Subjects

Foundation of Data Science
CS3352 3rd Semester CSE Dept | 2021 Regulation | 3rd Semester CSE Dept 2021 Regulation