Digital Principles and Computer Organization: Unit IV: Processor
Pipelining
Processor - Digital Principles and Computer Organization
We have seen various cycles involved in the instruction cycle. These fetch, decode and execute cycles for several instructions are performed simultaneously to reduce overall processing time. This process is referred to as instruction pipelining.
Pipelining
AU: May-07,12,13,15,16,17,19,
Dec.-06,08,09,14,15,16,18, June-08,09
• We have seen various cycles involved in
the instruction cycle. These fetch, decode and execute cycles for several
instructions are performed simultaneously to reduce overall processing time.
This process is referred to as instruction pipelining.
• To apply the concept of instruction
pipelining, we must subdivide instruction processing in number of stages as
given below.
S1 - Fetch (F): Read
instruction from the memory.
S2 - Decode (D): Decode the
opcode and fetch source operand (s) if necessary.
S3 - Execute (E): Perform the
operation specified by the instruction.
S4 - Store (S): Store the
result in the destination.
• Here, instruction processing is divided
into four stages hence it is known as four-stage instruction pipeline. With
this subdivision and assuming equal duration for each stage we can reduce the
execution time for 4 instructions from 16 time units to 7 time units. This is
illustrated in Fig. 7.8.1.
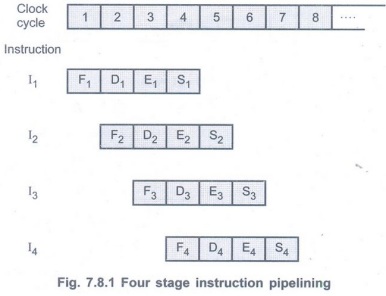
• In this instruction pipelining four
instructions are in progress at any given time. This means that four distinct
hardware units are needed, as shown in Fig. 7.8.2. These units are implemented
such that they are capable of performing their tasks simultaneously and without
interfering with one another. Information from the stage is passed to the next
stage with the help of buffers.

Example 7.8.1 Explain the function of a six segment pipeline and draw a space diagram for a six segment pipeline showing the time it takes to process eight tasks. AU May-07, Marks 8
Solution: Six stages in the pipeline :
1) Fetch Instruction (FI):
Read the next expected instruction into a buffer.
2) Decode Instruction (DI):
Determine the opcode and the operand specifiers.
3) Calculate Operands (CO):
Calculate the effective address of each source operand.
4) Fetch Operands (FO):
Fetch each operand from memory.

5) Execute Instruction (EI):
Perform the indicated operation and store the result, if any in the specified
destination operand location.
6) Write Operand (WO):
Store the result in memory.
Example 7.8.2
What is the ideal speed-up expected in a pipelined architecture with 'n'
stages? Justify your answer. AU May-07, Marks 2
Solution:
The pipelined processor ideally completes the processing of one instruction in
each clock cycle, which means that the rate of instruction processing with n
stage pipeline is n times that of sequential operation. Therefore, ideal
speed-up factor is n. However, such ideal performance of the pipeline is
achieved only when pipeline stages must complete their processing tasks for a
given instruction in the time allotted. Unfortunately, this is not the case;
pipeline operations could not sustained without interruption throughout the
program execution.
Pipeline Stages in the MIPS Instructions
1. Fetch instruction from memory.
2. Read registers while decoding the
instruction. The regular format of MIPS instructions allows reading and
decoding to occur simultaneously.
3. Execute the operation or calculate an
address.
4. Access an operand in data memory.
5. Write the result into a register.
Designing Instruction Sets for Pipelining
• From the following points we can
realized that the MIPS instruction set is designed for pipelined execution.
1. All MIPS instructions are the same
length. This restriction makes it much easier to fetch instructions in the
first pipeline stage and to decode them in the second stage.
2. MIPS has only a few instruction
formats, with the source register fields being located in the same place in
each instruction. Due to this symmetry the second stage can begin reading the
register file at the same time that the hardware is determining what type of
instruction was fetched.
3. Memory operands only appear in loads
or stores in MIPS. Due to this restriction we can use the execute stage to
calculate the memory address and then access memory in the following stage.
4. Since operands are aligned in memory,
data can be transferred between processor and memory in a single pipeline
stage.
Pipeline Hazards
• The timing diagram for instruction
pipeline operation shown in Fig. 7.8.3 (b) completes the processing of one
instruction in each clock cycle. This means that the rate of instruction
processing is four times that of sequential operation.
• The potential increase in performance
resulting from pipelining is proportional to the number of pipeline stages.
However, this increase would be achieved only if pipelined operation shown in
Fig. 7.8.3 (b) could be performed without any interruption throughout program
execution. Unfortunately, this is not the case.
• For many of reasons, one of the
pipeline stages may not be able to complete its operation in the allotted time.
• Fig. 7.8.4 shows an example in which
the operation specified in instruction 2 requires three cycles to complete,
from cycle 4 through cycle 6. Thus, in cycles 5 and 6, the information in
buffer B2 must remain intact until the instruction execution stage
has completed its operation. This means that stage 2 and in turn, stage 1 are
blocked from accepting new instructions because the information in B1
cannot be overwritten. Thus decode step for instruction and fetch step for
instruction 5 must be postponed as shown in the Fig. 7.8.4.
• The instruction pipeline shown in Fig.
7.8.4 is said to have been stalled for two clock cycles (clock cycles 5 and 6)
and normal pipeline operation resumes in clock cycle 7.
• Any reason that causes the pipeline to
stall is called a hazard.

Types of Hazards
1. Structural hazards:
These hazards are because of conflicts due to insufficient resources when even
with all possible combination, it may not be possible to overlap the operation.
2. Data or data dependent hazards:
These result when instruction in the pipeline depends on the result of previous
instructions which are still in pipeline and not completed.
3. Instruction or control hazards:
They arise while pipelining branch and other instructions that change the
contents of program counter. The simplest way to handle these hazards is to
stall the pipeline. Stalling of the pipeline allows few instructions to proceed
to completion while stopping the execution of those which results in hazards.
Structural Hazards
• The performance of pipelined processor
depends on whether the functional units are pipelined and whether they are
multiple execution units to allow all possible combination of instructions in
the pipeline. If for some combination, pipeline has to be stalled to avoid the
resource conflicts then there is a structural hazard.
• In other words, we can say that when
two instructions require the use of a given hardware resource at the same time,
the structural hazard occurs.
• The most common case in which this
hazard may arise is in access to memory. One instruction may need to access
memory for storage of the result while another
instruction or operand needed is being
fetched. If instructions and data reside in the same cache unit, only one
instruction can proceed and the other instruction is delayed. To avoid such
type of structural hazards many processors use separate caches for instruction
and data.
Data Hazards
• When either the source or the
destination operands of an instruction are not available at the time expected
in the pipeline and as a result pipeline is stalled, we say such a situation is
a data hazard.
• Consider a program with two ins
ructions, I1followed by I2. When this program is executed
in a pipeline, the execution of these two instructions can be performed
concurrently. In such case the result of I1 may not be available for
the execution of I2. If the result of I2 is dependent on
the result of I1 we may get incorrect result if both are executed
concurrently. For example, assume A = 10 in the following two operations :
I1: A ← A +5
I2: B← A×2
• When these two operations are performed
in the given order, one after the other, we get result 30. But if they are
performed concurrently, the value of A used in computing B would be the
original value, 10, leading to an incorrect result. In this case data used in
the I2 depend on the result of I1. The hazard due to such
situation is called data hazard or data dependent hazard. To avoid incorrect
results we have to execute dependent instructions one after the other
(in-order).
Control (Instruction) Hazards
• The purpose of the instruction fetch
unit is to supply the execution units with a steady stream of instructions.
This stream is interrupted when pipeline stall occurs either due to cache miss
or due to branch instruction. Such a situation is known as instruction hazard.
• Instruction hazard can cause greater
degradation in performance than data
hazards.
Unconditional
Branching
• Fig. 7.8.5 shows a sequence of
instructions being executed in a two-stage pipeline. The instruction I2
is a branch instruction and its target instruction is IK. In clock
cycle 3, the instruction I3 is fetched and at the same time branch
instruction (I2) is decoded and the target address is computed. In
clock cycle 4, the incorrectly fetched instruction I3 is discarded
and instruction IK is fetched. During this time execution unit is
idle and pipeline is stalled for one clock cycle.

Branch Penalty:
The time lost as a result of a branch instruction is often referred to as the
branch penalty.
Factor effecting branch penalty
1. It is more for complex instructions.
2. For a longer pipeline, branch penalty
is more..
• In case of longer pipelines, the branch
penalty can be reduced by computing the branch address earlier in the pipeline.
Review Questions
1. Explain the basic concepts of pipelining. AU: Dec.-06, 08, 09, June-08, 09, May-16, Marks 8
2. Explain basic operation of a four stage pipelining with a neat diagram. AU: Dec.-09, May-13, Marks 16
3. Discuss the basic concepts of pipelining. AU
May-12, Marks 8
4. State the pipeline stages in the MIPS
instructions.
5. Justify the statement: MIPS
instructions are designed for pipelining.
6. Discuss the various hazards that might arise in a pipeline. AU May-07, 09, Dec.-09, Marks 6
7. Define structural hazard, data hazard
and control hazard. AU: Dec.-08, Marks 2
8. Explain structural hazard.
9. Define: a. Pipeline frequency b.
Clock skewing
c. Pipeline throughput
d. Speedup factor e. Pipeline efficiency
f. Performance/cost ratio.
10. What is hazard? Explain its types with suitable example. AU: Dec.-14, May-17, Marks 16
11. Explain the different types of pipeline hazards with suitable examples. AU May-15,16, Dec.-18, Marks 16
12. Explain how the instruction pipeline
works? What are the various situations where an instruction pipeline can stall?
Illustrate with an example.
AU: Dec.-15, May-19, Marks 16
13. Explain how the instruction pipeline
works. What are the various situations where an instruction pipeline can stall? AU: Dec.-16, Marks 13
14. Explain the hazards caused by unconditional branching statements. AU May-17, Marks 7
Digital Principles and Computer Organization: Unit IV: Processor : Tag: : Processor - Digital Principles and Computer Organization - Pipelining
Related Topics
Related Subjects

Digital Principles and Computer Organization
CS3351 3rd Semester CSE Dept | 2021 Regulation | 3rd Semester CSE Dept 2021 Regulation