Artificial Intelligence and Machine Learning: Unit IV: Ensemble Techniques and Unsupervised Learning
Instance Based Learning: KNN(K-Nearest Neighbour)
Ensemble Techniques and Unsupervised Learning - Artificial Intelligence and Machine Learning
K-Nearest Neighbour is one of the only Machine Learning algorithms based totally on supervised learning approach. K-NN algorithm assumes the similarity between the brand new case/facts and available instances
Instance
Based Learning: KNN
•
K-Nearest Neighbour is one of the only Machine
Learning algorithms based totally on supervised learning approach.
•
K-NN algorithm assumes the similarity between the
brand new case/facts and available instances and placed the brand new case into
the category that is maximum similar to the to be had classes.
•
K-NN set of rules shops all of the to be had facts
and classifies a new statistics point based at the similarity. This means when
new data seems then it may be effortlessly categorised into a properly suite
class by using K-NN algorithm.
•
K-NN set of rules can be used for regression as well
as for classification however normally it's miles used for the classification
troubles.
•
K-NN is a non-parametric algorithm, because of this
it does no longer makes any is a non-pat assumption on underlying data.
•
It is also referred to as a lazy learner set of rules
because it does no longer research from the training set immediately as a
substitute it shops the dataset and at the time of class, it plays an movement
at the dataset.
•
The KNN set of rules at the schooling section simply
stores the dataset and when it gets new data, then it classifies that
statistics into a class that is an awful lot similar to the brand new data.
•
Example: Suppose, we've an picture of a creature that
looks much like cat and dog, but we want to know both it is a cat or dog. So
for this identity, we are able to use the KNN algorithm, because it works on a
similarity degree. Our KNN version will discover the similar features of the
new facts set to the cats and dogs snap shots and primarily based on the most
similar functions it will place it in both cat or canine class.
Why Do We Need KNN?
•
Suppose there are two categories, i.e., category A
and category B and we've a brand new statistics point x1, so this fact point
will lie within of these classes. To solve this sort of problem, we need a K-NN
set of rules. With the help of K-NN, we will without difficulty discover the
category or class of a selected dataset. Consider the underneath diagram:

How Does KNN Work ?
•
The K-NN working can be explained on the basis of the
below algorithm:
Step
1: Select the wide variety K of the acquaintances.
Step
2: Calculate the Euclidean distance of K variety of friends.
Step
3: Take the K nearest neighbors as according to the calculated
Euclidean distance.
Step
4: Among these ok pals, count number the number of the data points
in each class.
Step
5: Assign the brand new records points to that category for which
the quantity of the neighbor is maximum.
Step
6: Our model is ready.
•
Suppose we've got a brand new information point and
we want to place it in the required category. Consider the under image
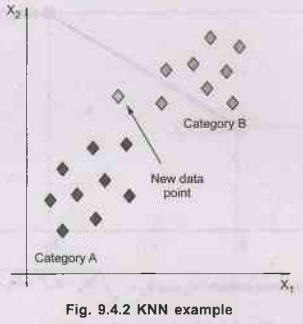
•
Firstly, we are able to pick the number of friends,
so we are able to select the ok = 5.
•
Next, we will calculate the Euclidean distance
between the facts points. The Tab Euclidean distance is the gap between points,
which we've got already studied in geometry. It may be calculated as:
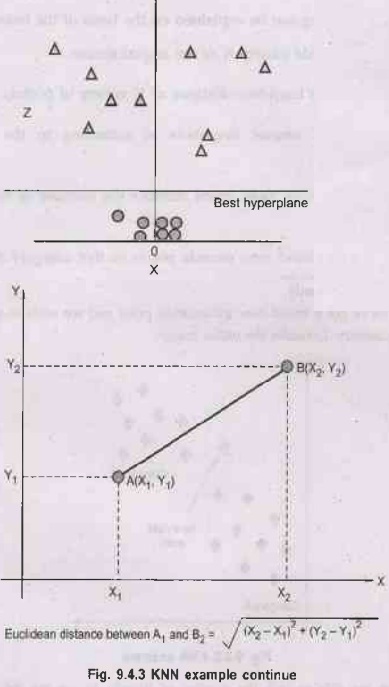
• By calculating the Euclidean distance we got the nearest
acquaintances, as 3 nearest neighbours in category A and two nearest associates
in class B. Consider the underneath image.
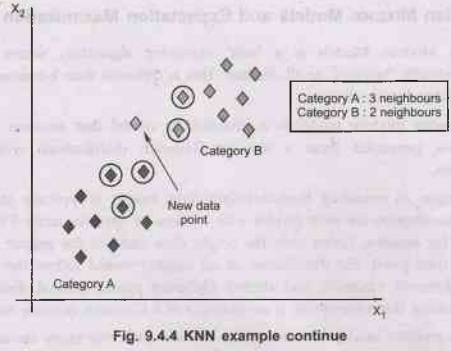
•
As we are able to see the three nearest acquaintances
are from category A, bob subsequently this new fact point must belong to
category A.
Difference between K-means and KNN

Artificial Intelligence and Machine Learning: Unit IV: Ensemble Techniques and Unsupervised Learning : Tag: : Ensemble Techniques and Unsupervised Learning - Artificial Intelligence and Machine Learning - Instance Based Learning: KNN(K-Nearest Neighbour)
Related Topics
Related Subjects

Artificial Intelligence and Machine Learning
CS3491 4th Semester CSE/ECE Dept | 2021 Regulation | 4th Semester CSE/ECE Dept 2021 Regulation