Artificial Intelligence and Machine Learning: Unit I(d): Heuristic Search Strategies - Local Search and Optimization Problems
Handling Unknown Environments
Heuristic Search Strategies - Local Search and Optimization Problems - Artificial Intelligence and Machine Learning
Earlier algorithms we have seen are offline search algorithms. They compute a complete solution before setting foot in the real world, and then execute the solution without considering new percepts.
Handling
Unknown Environments
•
Earlier algorithms we have seen are offline search
algorithms. They compute a complete solution before setting foot in the real
world, and then execute the solution without considering new percepts. Now we
will consider how to handle dynamic or semidynamic environments.
Online Search Agents
1)
The online search agent works on the concept of interleaving of two tasks
namely computation and action. In the real-world, the agent perform an action
and it observes the environment and then work out on the next action.
2)
If an environment is dynamic or semidynamic or stochastic the online search
work in best manner.
3)
An agent needs to pay a penalty for lengthy computation and for sitting around.
4)
An offline search is costly. For offline search we need to have proper planning
which consider all related information. In online search there is no need of
planning just see what happens and act accordingly.
Example
- Chess moves
5)
In online search the states and actions are unknown to the agent. Thus it has
an exploration problem. (it needs to explore the world).
6)
In an online search the actions are used to predict next states and actions.
7)
For predicting next states and actions computations are performed.
For
example -
•
Consider example of robot who builds a map between 2
locations say LOC 1 and LOC 2. For building a map robot needs to explore the
world so as to reach to LOC 2 from LOC 1. Parallely it will build the map.
•
A natural real world example of exploration problem
and online search is a baby trying to understand the world around it. It is
baby's online search process. A baby tries an action and go in certain state.
It keeps on doing this, gathering new experience and learning from it.
Solving Online Search Problems
1)
The purely computation process cannot handle an online search problem properly.
Agent needs to execute actions for solving problem.
2)
The agent has knowledge about -
a) ACTIONS
(s) which returns a list of actions allowed in state s.
b)
The step-cost function cost (s1, a, s') (note that cost function cannot be used
until the agent knows that s' is the outcome).
c)
GOAL-TEST (s)
3)
It is not possible for agent to access the successors of a state. In fact the
agent try related actions, in that state.
4)
As basic objective of an agent is to minimize cost, the goal state must be found
with minimum cost.
5)
The another possible goal can be to explore the entire environment. The total
path cost is cost of path across which the agent travels.
6)
In the online algorithm we can find the competitive ratio means shortest path.
The competitive ratio must be very small. But in reality many a time
competitive ratio is infinite.
7)
If the online search is with irreversible action then it will reach to a
dead-end state and from that state it can't achieve goal state.
8)
We must build an algorithm which does not explore dead-end path. But accidently
or in reality an algorithm can avoid dead ends in all state spaces.
9)
Consider two goal state space as shown in Fig. 4.4.1.
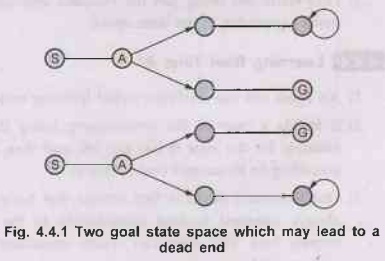
In
the Fig. 4.4.1 online search algorithm visit states S and A, both the state
spaces are identical so it must be explored in both cases. One link is to goal
state (G) and other lead to dead end in both states spaces. It is an example of
an adversary arguments. The exploration of state space is in an adversary
manner. One can put the goals and dead ends likewise.
Online Local Search
Hill
climbing search
1)
Hill climbing search has the property of locality in its node expansions
because it keeps just one current state in memory, hill-climbing search is
already an online search algorithm.
2)
Unfortunately, it is not very useful in its simplest form because it leaves the
agent sitting at local maxima with nowhere to go.
3)
Moreover, random restarts cannot be used, because the agent cannot transport
itself to a new state.
Random
walk
1) Instead
of random restarts, one might consider using a random walk to explore the
environment.
2) A
random walk simply selects at random one of the available actions from the
current state; preference can be given to actions that have not yet been tried.
3) It
is easy to prove that a random walk will eventually find a goal or complete its
exploration, provided that the space is finite.
Hill
climbing with memory
1)
Augmenting hill climbing with memory rather than randomness turns out to be a
more effective approach.
2)
The basic idea is to store a "current best estimate", H(S) the cost
to reach the goal from each state that has been visited.
3)
H(S) starts out being just the heuristic estimate h(s) and is updated as the
agent gains experience in the state space.
Learning Real Time A*
1)
An agent can use a scheme called learning real-time A* (LRTA*).
2)
It builds a map of the environment using the result table. It updates the cost
estimate for the state it has just left and then chooses the "apparently
best" move according to its current cost estimates.
3)
One important detail is that actions that have not yet been tried in a state S
are always assumed to lead immediately to the goal with the least possible
cost, namely h(s). This optimism under uncertainty encourages the agent to
explore new, possibly promising paths.
4)
An LRTA* agent is guaranteed to find a goal in any finite, safely explorable en
environment.
5)
It is not complete for infinite state spaces. There are cases where it can be
led infinitely astray. It can explore an environment of n states in O(n2)
steps in the worst case.
Learning in Online Search
At
every step online search agent can learn various aspects of current situation.
The
agents learn a "map" of the environment - more precisely, the outcome
of each action in each state-simply by recording each of their experiences.
The
local search agents acquire more accurate estimates of the value of each state
by using local updating rules.
By
learning, the agent can do better searching.
Review
Questions
1.
When is the class of problem said to be intractable? (Refer section 4.1)
2.
What is the power of heuristic search? Why does one go for heuristic search?
(Refer
section 4.1.10)
3.
What are the advantages of heuristic function? (Refer section 4.1)
4.
When a heuristic function h is said to be admissible? Give an admissible
heuristic function for TS. (Refer section 4.1.10)
5.
What is heuristic search? (Refer section 4.1.10)
6.
Explain heuristic search with an example. (Refer section 4.1.10)
7.
How to minimize total estimated solution cost using A* search with an example?
(Refer
section 4.1.6)
8.
Explain the A* search and give the proof of optimality of A*. (Refer section
4.1.6)
9.
What is heuristic? For each of the following type of problem give good
heuristics function.
i)
Block world problem ii) Missionaries and cannibals. (Refer section 4.1.10)
10.
What is heuristics? A* search uses a combined heuristic to select the best path
to follow through the state space toward the goal. Define the two heuristics
used (h(n) and g(n)). (Refer section 4.1.10)
11.
Best first search used both OPEN list and a CLOSED list. Describe the purpose
of each for the Best-First algorithm. Explain with suitable example. (Refer
section 4.1)
12.
What is heuristics? Explain any heuristics search method. Justify how
heuristics function helps in achieving goal state. (Refer section 4.1.10)
13.
State the reason when hill climbing often get stuck. (Refer section 4.2.2)
14.
What do you mean by local maxima with respect to search technique? (Refer
section 4.2.2)
15.
Describe hill climbing, random restart hill climbing and simulated annealing
algorithms. Compare their merits and demerits. (Refer section 4.2)
16.
How does hill climbing ensure greedy local search? What are the problems of
hill climbing? (Refer section 4.2)
17.
How does genetic algorithm come up with optimal solution? (Refer section
4.2.6)
Artificial Intelligence and Machine Learning: Unit I(d): Heuristic Search Strategies - Local Search and Optimization Problems : Tag: : Heuristic Search Strategies - Local Search and Optimization Problems - Artificial Intelligence and Machine Learning - Handling Unknown Environments
Related Topics
Related Subjects

Artificial Intelligence and Machine Learning
CS3491 4th Semester CSE/ECE Dept | 2021 Regulation | 4th Semester CSE/ECE Dept 2021 Regulation