Artificial Intelligence and Machine Learning: Unit IV: Ensemble Techniques and Unsupervised Learning
Ensemble Learning
Ensemble Techniques and Unsupervised Learning - Artificial Intelligence and Machine Learning
The idea of ensemble learning is to employ multiple learners and combine their predictions. If we have a committee of M models with uncorrelated errors, simply by averaging them the average error of a model can be reduced by a factor of M.
Ensemble Learning
•
The idea of ensemble learning is to employ multiple
learners and combine their predictions. If we have a committee of M models with
uncorrelated errors, simply by averaging them the average error of a model can
be reduced by a factor of M.
•
Unformtunately, the key assumption that the errors
due to the individual models are uncorrelated is unrealistic; in practice, the
errors are typically highly correlated, so the reduction in overall error is
generally small.
•
Ensemble modeling is the process of running two or
more related but different analytical models and then synthesizing the results
into a single score or spread in order to improve the accuracy of predictive
analytics and data mining applications.
•
Ensembles of classifiers is a set of classifiers
whose individual decisions combined in some way to classify new examples.
•
Ensemble methods combine several decision trees
classifiers to produce better predictive performance than a single decision
tree classifier. The main principle behind the ensemble model is that a group
of weak learners come together to form a strong learner, thus increasing the
accuracy of the model.
•
Why do ensemble methods work?
•
Based on one of two basic observations :
1.
Variance reduction: If the training sets are
completely independent, it will always helps to average an ensemble because
this will reduce variance without affecting bias (e.g., bagging) and reduce
sensitivity to individual data points.
2.
Bias reduction: For simple models, average
of models has much greater capacity than single model Averaging models can
reduce bias substantially by increasing capacity and control variance by
Citting one component at a time.
Bagging
•
Bagging is also called Bootstrap aggregating. Bagging
and boosting are meta - algorithms that pool decisions from multiple classifiers.
It creates ensembles feed by repeatedly randomly resampling the training data.
•
Bagging was the first effective method of ensemble
learning and is one of the simplest methods of arching. The meta- algorithm,
which is a special case of the model averaging, was originally designed for
classification and is usually applied to decision tree models, but it can be
used with any type of model for classification or regression.
•
Ensemble classifiers such as bagging, boosting and
model averaging are known to have improved accuracy and robustness over a
single model. Although unsupervised models, such as clustering, do not directly
generate label prediction for each individual, they provide useful constraints
for the joint prediction of a set of related objects.
•
For given a training set of size n, create m samples
of size n by drawing n examples from the original data, with replacement. Each
bootstrap sample will on average contain 63.2 % of the unique training
examples, the rest are replicates. It combines the m resulting models using
simple majority vote.
•
In particular, on each round, the base learner is
trained on what is often called a "bootstrap replicate" of the
original training set. Suppose the training set consists motor of n examples.
Then a bootstrap replicate is a new training set that also consists of n
examples, and which is formed by repeatedly selecting uniformly at random and
with replacement n examples from the original training set. This means that the
same example may appear multiple times in the bootstrap replicate, or it may
appear not at all.
•
It also decreases error by decreasing the variance in
the results due to unstable learners, algorithms (like decision trees) whose
output can change dramatically when the training data is slightly changed.
Pseudocode:
1.
Given training data (x1, y1), ..., (xm, Ym)
2.
For t = 1,..., T:
a.
Form bootstrap replicate dataset St by selecting m random examples
from the training set with replacement.
b.
Let ht be the result of training base learning algorithm on St.
3.
Output combined classifier:
H(x)
= majority (h1(x), ..., hT (x)).
Bagging
Steps:
1.
Suppose there are N observations and M features in training data set. A sample
aside from training data set is taken randomly with replacement.
2. A
subset of M features is selected randomly and whichever feature gives the best
split is used to split the node iteratively.
3.
The tree is grown to the largest.
4.
Above steps are repeated n times and prediction is given based on the
aggregation of predictions from n number of trees.
Advantages
of Bagging:
1.
Reduces over -fitting of the model.
2.
Handles higher dimensionality data very well.
3.
Maintains accuracy for missing data.
Disadvantages
of Bagging:
1.
Since final prediction is based on the mean predictions from subset trees, it
won't give precise values for the classification and regression model.
Boosting
•
Boosting is a very different method to generate
multiple predictions (function mob estimates) and combine them linearly.
Boosting refers to a general and provably effective method of producing a very
accurate classifier by combining rough and moderately inaccurate rules of
thumb.
•
Originally developed by computational learning
theorists to guarantee performance improvements on fitting training data for a
weak learner that only needs to generate a hypothesis with a training accuracy
greater than 0.5. Final result is the weighted sum of the results of weak
classifiers.
•
A learner is weak if it produces a classifier that is
only slightly better than random guessing, while a learner is said to be strong
if it produces a classifier that achieves a low error with high confidence for
a given concept.
•
Revised to be a practical algorithm, AdaBoost, for
building ensembles that empirically improves generalization performance.
Examples are given weights. At each iteration, a new hypothesis is learned and
the examples are reweighted to focus the system on examples that the most
recently learned classifier got wrong.
•
Boosting is a bias reduction technique. It typically
improves the performance of a single tree model. A reason for this is that we
often cannot construct trees which are sufficiently large due to thinning out
of observations in the terminal nodes.
•
Boosting is then a device to come up with a more
complex solution by taking linear combination of trees. In presence of
high-dimensional predictors, boosting is also very useful as a regularization
technique for additive or interaction modeling.
•
To begin, we define an algorithm for finding the
rules of thumb, which we call a weak learner. The boosting algorithm repeatedly
calls this weak learner, each time feeding it a different distribution over the
training data. Each call generates a weak classifier and we must combine all of
these into a single classifier that, hopefully, is much more accurate than any
one of the rules.
•
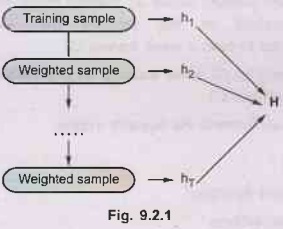
Train a set of weak hypotheses: h1,..., hT.
The combined hypothesis H is a weighted majority vote of the T weak hypotheses.
During the training, focus on the examples that are misclassified.
AdaBoost:
•
AdaBoost, short for "Adaptive Boosting", is
a machine learning meta - algorithm formulated by Yoav Freund and Robert
Schapire who won the prestigious "Gödel Prize" in 2003 for their
work. It can be used in conjunction with many other types of learning
algorithms to improve their performance.
•
It can be used to learn weak classifiers and final
classification based on weighted vote of weak classifiers.
•
It is linear classifier with all its desirable properties.
It has good generalization properties.
•
To use the weak learner to form a highly accurate
prediction rule by calling the weak learner repeatedly on different
distributions over the training examples.
•
Initially, all weights are set equally, but each
round the weights of incorrectly classified examples are increased so that
those observations that the previously classifier poorly predicts receive
greater weight on the next iteration.
•
Advantages of AdaBoost:
1.
Very simple to implement
2.
Fairly good generalization
3.
The prior error need not be known ahead of time.
•
Disadvantages of AdaBoost:
1.
Sub optimal solution
2.
Can over fit in presence of noise.
Boosting
Steps:
1.
Draw a random subset of training samples d1 without replacement from the training
set D to train a weak learner C1
2.
Draw second random training subset d2 without replacement from the training set
and add 50 percent of the samples that were previously falsely
classified/misclassified to train a weak learner C2
3.
Find the training samples d3 in the training set D on which C1 and C2 disagree
to train a third weak learner C3
4.
Combine all the weak learners via majority voting.
Advantages
of Boosting:
1.
Supports different loss function.
2.
Works well with interactions.
Disadvantages
of Boosting:
1.
Prone to over-fitting.
2.
Requires careful tuning of different hyper - parameters.
Stacking
•
Stacking, sometimes called stacked generalization, is
an ensemble machine learning method that combines multiple heterogeneous base
or component models via a meta-model.
•
The base model is trained on the complete training
data, and then the meta-model is trained on the predictions of the base models.
The advantage of stacking is the ability to explore the solution space with
different models in the same problem.
•
The stacking based model can be visualized in levels
and has at least two levels of the models. The first level typically trains the
two or more base learners(can be heterogeneous) and the second level might be a
single meta learner that utilizes the base models predictions as input and
gives the final result as output. A stacked model can have more than two such
levels but increasing the levels doesn't always guarantee better performance.
•
In the classification tasks, often logistic regression
is used as a meta learner, while linear regression is more suitable as a meta
learner for regression-based tasks.
•
Stacking is concerned with combining multiple
classifiers generated by different learning algorithms L1,..., LN
on a single dataset S, which is composed by a feature vector S1 = (xi,
ti).
•
The stacking process can be broken into two phases:
1.
Generate a set of base - level classifiers C1,..., CN
where Ci = Li (S)
2.
Train a meta - level classifier to combine the outputs of the base –
level classifiers.
•
Fig. 9.2.2 shows stacking frame.
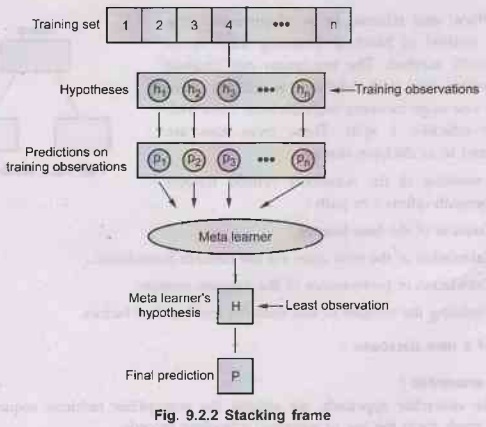
•
The training set for the meta- level classifier is
generated through a leave - one - out cross validation process.
![]() i
= 1, ..., n and
i
= 1, ..., n and ![]() k = 1,..., N: Cjk
k = 1,..., N: Cjk
= Lk
(S-si)
•
The learned classifiers are then used to generate
predictions for si : ŷki = Cki
(xi)
•
The meta- level dataset consists of examples of the
form ((ŷ,...,ŷni), yi), where the features are
the predictions of the base - level classifiers and the class is the correct
class of the example in hand.
•
Why do ensemble methods work?
•
Based on one of two basic observations:
1. Variance
reduction: If the training sets are completely
independent, it will always helps to average an ensemble because this will
reduce variance without affecting bias (e.g. - bagging) and reduce sensitivity
to individual data points.
2.
Bias reduction: For simple models, average
of models has much greater capacity than single model Averaging models can
reduce bias substantially by increasing capacity and control variance by
Citting one component at a time.
Adaboost
•
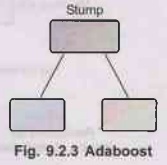
AdaBoost also referred to as adaptive boosting Stumpis
a method in Machine Learning used as an ensemble method. The maximum not
unusual algorithm used with AdaBoost is selection trees with one stage meaning
with decision trees with most effective 1 split. These trees also are referred
to as decision stumps.
•
The working of the AdaBoost version follows the
beneath-referred to path:
•
Creation of the base learner.
•
Calculation of the total error via the beneath
formulation.
•
Calculation of performance of the decision stumps.
•
Updating the weights in line with the misclassified
factors.
Creation
of a new database:
AdaBoost
ensemble:
•
In the ensemble approach, we upload the susceptible
fashions sequentially and then teach them the use of weighted schooling
records.
•
We hold to iterate the process till we gain the
advent of a pre-set range of vulnerable learners or we can not look at further
improvement at the dataset. At the end of the algorithm, we are left with some
vulnerable learners with a stage fee.
Difference between Bagging and Boosting

Artificial Intelligence and Machine Learning: Unit IV: Ensemble Techniques and Unsupervised Learning : Tag: : Ensemble Techniques and Unsupervised Learning - Artificial Intelligence and Machine Learning - Ensemble Learning
Related Topics
Related Subjects

Artificial Intelligence and Machine Learning
CS3491 4th Semester CSE/ECE Dept | 2021 Regulation | 4th Semester CSE/ECE Dept 2021 Regulation