Database Management System: Unit V: Advanced Topics
Distributed Databases
Advanced Topics - Database Management System
A distributed database system consists of loosely coupled sites (computer) that share no physical components and each site is associated a database system.
Unit: V: Advanced Topics
Syllabus
Distributed Databases: Architecture,
Data Storage, Transaction Processing, Query processing and optimization - NOSQL
Databases: Introduction - CAP Theorem - Document Based systems - Key value
Stores - Column Based Systems - Graph Databases. Database Security: Security
issues - Access control based on privileges - Role Based access control - SQL
Injection - Statistical Database security - Flow control - Encryption and
Public Key infrastructures - Challenges.
Distributed Databases
AU: Dec.-04,07,16,17,19,
May-03,06,14,16,17,19, Marks 16
Definition of distributed databases:
• A distributed database system
consists of loosely coupled sites (computer) that share no physical components
and each site is associated a database system.
• The software that maintains and manages the working
of distributed databases is called distributed database management system.
• The database system that runs on
each site is independent of each other. Refer Fig. 5.1.1.

The transactions can access data at one or more sites.
Advantages of distributed database system
(1) There is fast data processing as several sites participate in
request processing. 2.
(2) Reliability and availability
of this system is high.
(3) It possess reduced operating cost.
(4) It is easier to expand the
system by adding more sites.
(5) It has improved sharing ability and local
autonomy.
Disadvantages of distributed database system
(1) The system becomes complex to manage and control.
(2) The security issues must be carefully managed.
(3) The system require deadlock handling during the
transaction processing otherwise the entire system may be in inconsistent
state.
(4) There is need of some standardization for
processing of distributed database system.
Difference between distributed DBMS and centralized
DBMS

Uses of distributed system:
(1) Often distributed databases are used by organizations that have
numerous offices in different geographical locations. Typically an individual
branch is interacting primarily with the data that pertain to its own
operations, with a much less frequent need for general company data. In such a
situation, distributed systems are useful.
(2) Using distributed system, one can give permissions to single
sections of the overall database, for better internal and external protection.
(3) If we need to add a new location to a business, it is simple to
create an additional node within the database, making distribution highly
scalable.
Types of Distributed Databases
There are two types of distributed databases -
(1) Homogeneous databases
• The homogeneous databases are kind
of database systems in which all sites have identical software running on them.
Refer Fig. 5.1.2.

• In this system, all the sites are aware of the
other sites present in the system and they all cooperate in processing user's
request.
• Each site present in the system, surrenders part of
its autonomy in terms of right to change schemas or software.
• The homogeneous database system
appears as a single system to the user.
(2) Heterogeneous databases
• The heterogeneous databases are kind
of database systems in which different sites have different schema or software.
Refer Fig. 5.1.3.

• The participating sites are not aware of other
sites present in the system.
• These sites provide limited
facilities for cooperation in transaction processing.
Architecture
• Following is an architecture of
distributed databases. In this architecture the local database is maintained by
each site.
• Each
site is interconnected by communication network.
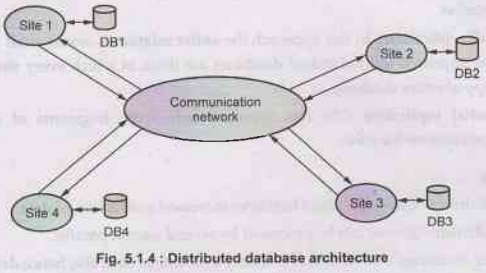
When user makes a request for particular data at site Si
then it is first searched at the local database. If the data is not present in
the local database then the request for that data is passed to all the other
sites via communication network. Each site then searches for that data at its
local database. When data is found at particular site say Sj then it is
transmitted to site Si via communication network.
Data Storage
There are two approaches of storing relation r in distributed database -
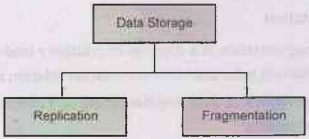
(1) Replication: System maintains multiple copies of data,
stored in different sites, for grind faster retrieval and fault tolerance.
(2) Fragmentation: Relation is partitioned
into several fragments stored in distinct sites.
Data Replication
• Concept: Data replication means storing a
copy or replica of a relation fragments in two or more sites.
• There are two methods of data
replication replication. (1) Full replication (2) Partial
replication
• Full replication: In this approach the
entire relation is stored at all the sites. In this approach full redundant
databases are those in which every site contains a copy of entire database.
• Partial replication: In this approach only
some fragments of relation are replicated on the sites.
Advantages:
(1) Availability: Data
replication facilitates increased availability of data.
(2) Parallelism: Queries can be processed by several sites in
parallel.
(3) Faster accessing: The relation r is locally available at each site, hence data accessing
becomes faster.
Disadvantages:poi
(1) Increased cost of update: The major disadvantage of data
replication is increased betcost of updated. That means each replica of
relation r must be updated from all the sites if user makes a request for some
updates in relation.
(2) Increased complexity in concurrency control: It becomes complex to
implement the concurrency control mechanism for all the sites containing
replica.
Data Fragmentation
• Concept: Data fragmentation is a division of relation r into fragments r1,r2,
r3,...,rn which contain sufficient information to reconstruct relation r.
• There are two approaches of data fragmentation -
(1) Horizontal fragmentation and (2) Vertical fragmentation.
• Horizontal fragmentation: In this approach, each tuple of r is assigned to one or more fragments.
If relation R is fragmented in r1 and r2 fragments, then to bring these
fragments back to R we must use union operation. That means R=r1ur2
• Vertical fragmentation: In this approach, the relation r is fragmented based on one or more
columns. If relation R is fragmented into r1 and r2 fragments using vertical
fragmentation then to bring these fragments back to original relation R we must
use join operation. That means R= r1 r2
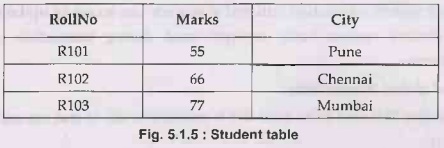
• For example - Consider following
relation r
Student(RollNo, Marks, City)
The values in this schema are inserted as
Horizontal Fragmentation 1:
SELECT * FROM Student WHERE Marks >50 AND
City='Pune'
We will get

Horizontal Fragmentation 2:
SELECT * FROM Student WHERE Marks >50 AND City="Mumbai'
We will get

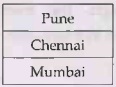
Vertical Fragmentation 1 :
SELECT * FROM RollNo

Vertical Fragmentation 2:
SELECT * FROM city
Transaction Processing
Basic Concepts
In distributed system transaction initiated at one site can access or
update data at other sites. Let us discuss various basic concepts used during
transaction processing in distributed systems -
• Local and global transactions :
Local transaction Ti is said to be local if it is initiated
at site Si and can access or update data at site Si only.
Global transaction Ti initiated by site Si is said to be
global if it can access or update data at site Si, Sj,Sk and so on.
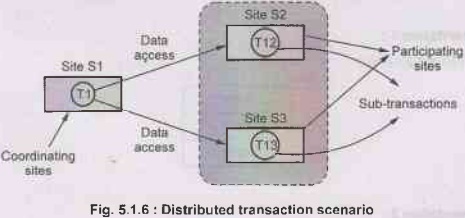
• Coordinating and participating sites:
The site at which the transaction is initiated is called coordinating
site. The participating sites are those sites at which the sub-transactions are
executing. For example - If site S1 initiates the transaction T1 then it is
called coordinating site. Now assume that transaction T1 (initiated at S1) can
access site S2 and S3. Then sites S2 and S3 are called participating sites.
To access the data on site S2, the transaction T1 needs
another transaction T12 on site S2 similarly to access the data on site S3, the
transaction T2 needs some transaction say T13 on site S3. Then transactions T12
and T13 are called sub-transactions. The above described scenario can be
represented by following Fig. 5.1.6.
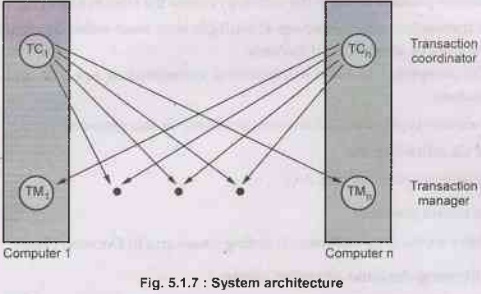
• Transaction manager :
The transaction manager manages the execution of those transactions (or
subtransactions) that access data stored in a local site.
(1) To maintain the log for recovery purpose.
(2) Participating in coordinating the concurrent execution of the
transactions executing balls at that site.
• Transaction coordinator:
The transaction coordinator coordinates the execution of the
various transactions (both local and global) initiated at that site.
The tasks of Transaction coordinator are -
(1) Starting the execution of transactions that originate at the site.
(2) Distributing subtransactions at appropriate sites for
execution
Let TC denotes the transaction coordinator and TM denotes the
transaction manager, then the system architecture can be represented as,
Failure Modes
There are four types of failure modes,
1. Failure of site
2. Loss of messages
3. Failure of communication link
4. Network partition
The most common type of failure in distributed system is
loss or corruption of messages. The system uses Transmission Control
Protocol(TCP) to handle such error. This is a standard connection oriented
protocol in which message is transmitted from one end to another using wired
connection.
• If two nodes are not
directly connected, messages from one to another must be routed through
sequence of communication links. If the communication link fails, the messages
are rerouted by alternative links.
• A system is partitioned if it has
been split into two subsystems. This is called partitions. Lack of connection
between the subsystems also cause failure in distributed system.
Commit Protocols
Two Phase Commit Protocol
• The atomicity is an important property of any
transaction processing. What is this atomicity property? This property means
either the transaction will execute completely or it won't execute at all.
• The commit protocol ensures the atomicity across
the sites in following ways -
i) A transaction which executes at multiple sites must
either be committed at all the sites, or aborted at all the sites.
ii) Not acceptable to have a transaction committed at one site and aborted at another.
• There are two types of important
sites involving in this protocol -
• One Coordinating site
• One or more participating sites.
Two phase commit protocol
This protocol works in two phases - i) Voting phase and ii) Decision
phase.
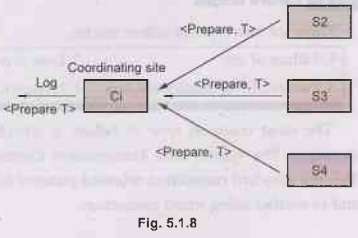
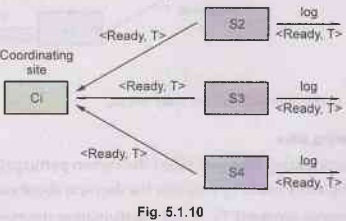
Phase 1: Obtaining decision or voting phase
Step 1: Coordinator
site Ci asks all participants to prepare to commit transaction Ti.
• Ci adds the records <prepareT> to the log and writes
the log to stable storage.
• It then sends prepare T messages to all participating sites at which T will get executed.
Step 2: Upon
receiving message, transaction manager at participating site determines if it
can commit the transaction
• If not, add a record <no T> to the log and send abort
T message to coordinating site Ci.
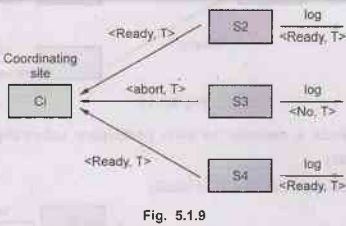
• If the transaction can be committed, then :
• Add the record <ready T> to the log
• Force all records for T to stable storage
• Send ready T message to
Ci.
Phase 2: Recoding decision phase
• T can be committed of Ci received a ready T message
from all the participating sites otherwise T must be aborted.o
• Coordinator adds a decision record, <commit
T> or <abort T>, to the log and forces record onto stable storage.
Once the record stable storage it is irrevocable (even if failures occur)
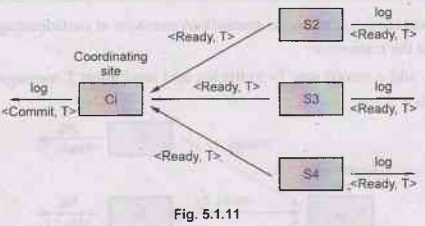
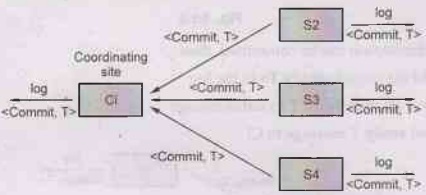
• Coordinator sends a message to each
participant informing it of the decision
(commit or abort)
• Participants take appropriate action locally.
Failure of site
There are various cases at which failure may occur,
(1) Failure of participating sites
• If any of the participating sites gets failed then
when participating site Si recovers, it examines the log entry made by it to
take the decision about executing transaction.
• If the log contains <commit T> record: participating site executes
redo (T)
• If the log contains <abort T> record: participating site executes
undo (T)
• If the log contains <ready T> record: participating site must
consult Coordinating site to take decision about execution of transaction T.
• If T committed, redo (T)
• If T aborted, undo (T)
• If the log of participating site contains no record
then that means Si gets failed before responding to Prepare T message from
coordinating site. In this case it must abort T
(2) Failure of coordinator
• If coordinator fails while the commit protocol for
T is executing then participating sites must take decision about execution
of transaction T:
i) If an active participating
site contains a <commit T> record in its log, then T site must be
committed.
ii) If an active participating site contains an <abort T> record
in its log, then T must be aborted.
iii) If some active participating site does not contain a <ready
T> record in its log, then the failed coordinator Ci cannot have decided to
commit T. Can therefore abort T.
iv) If none of the above cases holds, then all participating active
sites must have a <ready T> record in their logs, but no additional
control records (such as <abort T> of <commit T>). In this case
active sites must wait for coordinator site Ci to recover, to find decision.
Two phase locking protocol has blocking problem.
What is blocking problem?
It is a stage at which active participating sites may have to wait for
failed coordinator site to recover.
The solution to this problem is to use three phase locking protocol.
Three Phase Commit Protocol
• The three phase locking
is an extension of two phase locking protocol in which eliminates the blocking
problem.
• Various assumptions that
are made for three phase commit protocol are -
• No network partitioning.
• At any point at least one site must be up.
• At the most k sites (participating as well as coordinating) can fail.
• Phase 1: This phase is similar to phase 1 of two phase protocol. That means
Coordinator site Ci asks all participants to prepare to commit transaction Ti.
The coordinator then makes the decision about commit or abort based on the response
from all the participating sites.
• Phase 2: In phase 2 coordinator makes a decision as in 2 Phase Commit which is
called the pre-commit decision <Pre-commit, T>, and records it in
multiple (at least K) participating sites.
• Phase 3: In phase 3, coordinator sends commit/abort message to all participating
Brits sites.
• Under three phase protocol, the
knowledge of pre-commit decision can be used to commit despite coordinator site
failure. That means if the coordinating site in case gets failed then one of
the participating site becomes the coordinating site and der consults other
participating sites to know the Pre-commit message which they possess. Thus
using this pre-commit t message the decision about commit/abort is taken by
this new coordinating site.
• This protocol avoids blocking problem as long as
less than k sites fail.
Advantage of three phase commit protocol
(1) It avoid blocking problem.
Disadvantage of three phase commit protocol
(1) The overhead is increased.
Query Processing and Optimization
Distributed database query is processed using following
steps-
(1) Query Mapping:
• The input query on distributed data is specified
using query language.
• This query language is then translated into
algebraic query.
• During this translation the global conceptual
schema is referred.
• During the translation some important actions such
as normalization, analysis for semantic errors, simplification are carried out
then input query is restructured into algebraic query.
(2) Localization:
• In this step, the replication of information is
handled.
• The distributed query is mapped on
the global schema to separate queries on individual fragments.
(3) Global Query Optimization: optimization means selecting a strategy from list of candidate queries
which is closest to optimal. For optimization, the cost is computed. The total
cost is combination of CPU cost, I/O cost and communication costs.
(4) Local Query Optimization: This step is common to all sites in
distributed database. The techniques of local query optimization are similar to
those used in centralized systems.
Review Questions
1. What are the various features of distributed
database versus centralized database system? AU:
Dec.-17, Marks 6, May-17, Marks 8
2. Explain the architecture of a distributed
database. AU: Dec.-16, Marks 7
3. Explain about distributed databases and their
characteristics, functions and advantages and disadvantages. AU:
Dec.-07, May-14, Marks 8, May-16, Marks 16
4. Explain design of distributed database. AU: Dec.-04, Marks 8
5. Discuss homogeneous and heterogeneous databases reference
to distributed databases. AU:
May-03, Marks 8
6. Discuss in detail about the
distributed databases. AU: May-19,
Marks 13
7. What are data fragmentations? Explain various
approaches for fragmenting a relation with example. AU:
May-06, Marks 6
8. Explain in detail various approaches used for
storing a relation in distributed databases. AU: Dec.-04, Marks 8, Dec.-19, Marks
9
Database Management System: Unit V: Advanced Topics : Tag: : Advanced Topics - Database Management System - Distributed Databases
Related Topics
Related Subjects

Database Management System
CS3492 4th Semester CSE Dept | 2021 Regulation | 4th Semester CSE Dept 2021 Regulation