Artificial Intelligence and Machine Learning: Unit III: Supervised Learning
Decision Tree
Supervised Learning - Artificial Intelligence and Machine Learning
A decision tree is a simple representation for classifying examples. Decision tree learning is one of the most successful techniques for supervised classification learning.
Decision
Tree
•
A decision tree is a simple representation for
classifying examples. Decision tree learning is one of the most successful
techniques for supervised classification learning.
•
In decision analysis, a decision tree can be used to
visually and explicitly represent decisions and decision making. As the name
goes, it uses a tree-like model of decisions.
•
Learned trees can also be represented as sets of
if-then rules to improve human readability.
•
A decision tree has two kinds of nodes
1.
Each leaf node has a class label, determined by majority vote of training
examples reaching that leaf.
2.
Each internal node is a question on features. It branches out according to
the answers.
•
Decision tree learning is a method for approximating
discrete-valued target functions. The learned function is represented by a
decision tree.
•
A learned decision tree can also be re-represented as
a set of if-then rules. Decision tree learning is one of the most widely used
and practical methods for inductive inference.
•
It is robust to noisy data and capable of learning
disjunctive expressions.
•
Decision tree learning method searches a completely
expressive hypothesis
Decision Tree Representation
•
Goal: Build a
decision tree for classifying examples as positive or negative instances of a
concept
•
Supervised learning, batch processing of training
examples, using a preference bias.
•
A decision tree is a tree where
a. Each
non-leaf node has associated with it an attribute (feature).
b.
Each leaf node has associated with it a classification (+ or -).
C.
Each arc has associated with it one of the possible values of the attribute at
the node from which the arc is directed.
•
Internal node denotes a test on an attribute. Branch
represents an outcome of the test. Leaf nodes represent class labels or class
distribution.
•
A decision tree is a flow-chart-like tree structure,
where each node denotes a test on an attribute value, each branch represents an
outcome of the test, and tree leaves represent classes or class distributions.
Decision trees can easily be converted to classification rules.
Decision
Tree Algorithm
•
To generate decision tree from the training tuples of
data partition D.
Input:
1.
Data partition (D)
2.
Attribute list
3.
Attribute selection method
Algorithm:
1.
Create a node (N)
2. If
tuples in D are all of the same class then
3.
Return node (N) as a leaf node labeled with the class C.
4.
If attribute list is empty then return N as a leaf node labeled with the
majority class in D
5.
Apply attribute selection method (D, attribute list) to find the
"best" splitting criterion;
6.
Label node N with splitting criterion;
7. If
splitting attribute is discrete-valued and multiway splits allowed
8.
Then attribute list -> attribute list -> splitting attribute
9.
For (each outcome j of splitting criterion)
10.
Let Dj be the set of data tuples in D satisfying outcome j;
11.
If Dj is empty then attach a leaf labeled with the majority class in
D to node N;
12.
Else attach the node returned by Generate decision tree (Dj,
attribute list) to node N;
13.
End of for loop
14.
Return N;
•
Decision tree generation consists of two phases: Tree
construction and pruning
•
In tree construction phase, all the training examples
are at the root. Partition examples recursively based on selected attributes.
•
In tree pruning phase, the identification and removal
of branches that reflect noise or outliers.
•
There are various paradigms that are used for learning
binary classifiers which include:
1.
Decision Trees
2.
Neural Networks
3.
Bayesian Classification
4.
Support Vector Machines
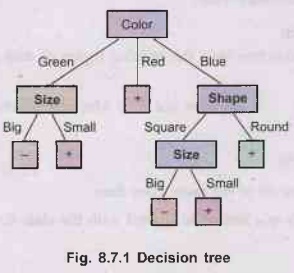
Example 8.7.1
Using following feature tree, write decision rules for majority class.
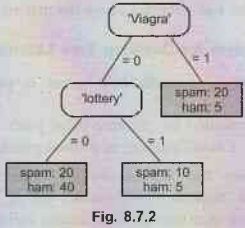
Solution: Left Side: A feature tree combining two Boolean features. Each
internal node or split is labelled with a feature, and each edge emanating from
a split is labelled with a feature value. Each leaf therefore corresponds to a
unique combination of feature values. Also indicated in each leaf is the class
distribution derived from the training set
•
Right Side: A feature tree partitions the instance
space into rectangular regions, one for each leaf.
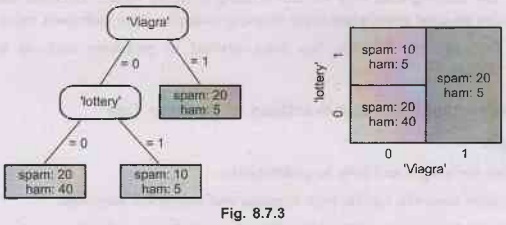
•
The leaves of the tree in the above figure could be
labelled, from left to right, as ham - spam - spam, employing a simple decision
rule called majority class.
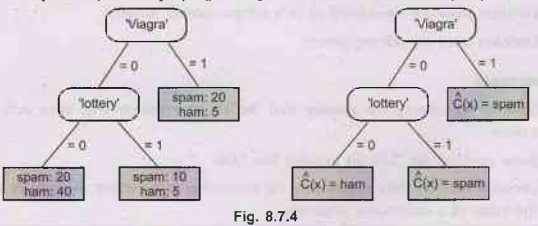
•
Left side: A feature tree with training set class distribution in the
leaves.
•
Right side: A decision tree obtained using the majority class decision
rule.
Appropriate Problem for Decision Tree Learning
•
Decision tree learning is generally best suited to
problems with the following characteristics:
1.
Instances are represented by attribute-value pairs. Fixed set of attributes,
and the attributes take a small number of disjoint possible values.
2.
The target function has discrete output values. Decision tree learning is
appropriate for a boolean classification, but it easily extends to learning
functions with more than two possible output values.
3. Disjunctive
descriptions may be required. Decision trees naturally represent disjunctive
expressions.
4.
The training data may contain errors. Decision tree learning methods are robust
to errors, both errors in classifications of the training examples and errors
in the attribute values that describe these examples.
5.
The training data may contain missing attribute values. Decision tree methods
can be used even when some training examples have unknown values.
6.
Decision tree learning has been applied to problems such as learning to
classify.
Advantages and Disadvantages of Decision Tree
Advantages:
1.
Rules are simple and easy to understand.
2.
Decision trees can handle both nominal and numerical attributes.
3.
Decision trees are capable of handling datasets that may have errors.
4.
Decision trees are capable of handling datasets that may have missing values.
5.
Decision trees are considered to be a non parametric method.
6.
Decision trees are self-explantory.
Disadvantages:
1.
Most of the algorithms require that the target attribute will have only
discrete values.
2.
Some problem are difficult to solve like XOR.
3.
Decision trees are less appropriate for estimation tasks where the goal is to
predict the value of a continuous attribute.
Artificial Intelligence and Machine Learning: Unit III: Supervised Learning : Tag: : Supervised Learning - Artificial Intelligence and Machine Learning - Decision Tree
Related Topics
Related Subjects

Artificial Intelligence and Machine Learning
CS3491 4th Semester CSE/ECE Dept | 2021 Regulation | 4th Semester CSE/ECE Dept 2021 Regulation