Foundation of Data Science: Unit I: Introduction
Data Preparation
Operations | Data Science
Data preparation means data cleansing, Integrating and transforming data.
Data
Preparation
• Data
preparation means data cleansing, Integrating and transforming data.
Data Cleaning
• Data
is cleansed through processes such as filling in missing values, smoothing the
noisy data or resolving the inconsistencies in the data.
• Data
cleaning tasks are as follows:
1. Data
acquisition and metadata
2. Fill
in missing values
3.
Unified date format
4.
Converting nominal to numeric
5.
Identify outliers and smooth out noisy data
6.
Correct inconsistent data
• Data
cleaning is a first step in data pre-processing techniques which is used to
find the missing value, smooth noise data, recognize outliers and correct
inconsistent.
• Missing value: These
dirty data will affects on miming procedure and led to unreliable and poor
output. Therefore it is important for some data cleaning routines. For example,
suppose that the average salary of staff is Rs. 65000/-. Use this value to
replace the missing value for salary.
• Data entry errors: Data
collection and data entry are error-prone processes. They often require human
intervention and because humans are only human, they make typos or lose their
concentration for a second and introduce an error into the chain. But data
collected by machines or computers isn't free from errors either. Errors can
arise from human sloppiness, whereas others are due to machine or hardware
failure. Examples of errors originating from machines are transmission errors
or bugs in the extract, transform and load phase (ETL).
• Whitespace error: Whitespaces tend to
be hard to detect but cause errors like other redundant characters would. To remove
the spaces present at start and end of the string, we can use strip() function
on the string in Python.
• Fixing capital letter mismatches:
Capital letter mismatches are common problem. Most programming languages make a
distinction between "Chennai" and "chennai".
• Python
provides string conversion like to convert a string to lowercase, uppercase
using lower(), upper().
• The
lower() Function in python converts the input string to lowercase. The upper()
Function in python converts the input string to uppercase.
Outlier
• Outlier
detection is the process of detecting and subsequently excluding outliers from
a given set of data. The easiest way to find outliers is to use a plot or a
table with the minimum and maximum values.
• Fig. 1.6.1 shows outliers detection. Here O1 and O2 seem outliers from the rest.
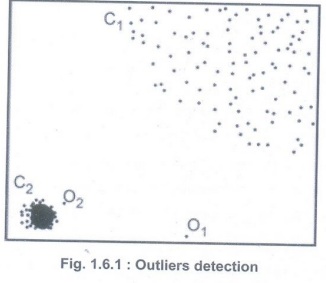
• An
outlier may be defined as a piece of data or observation that deviates
drastically from the given norm or average of the data set. An outlier may be
caused simply by chance, but it may also indicate measurement error or that the
given data set has a heavy-tailed distribution.
•
Outlier analysis and detection has various applications in numerous fields such
as fraud detection, credit card, discovering computer intrusion and criminal
behaviours, medical and public health outlier detection, industrial damage
detection.
•
General idea of application is to find out data which deviates from normal
behaviour of data set.
Dealing with Missing Value
• These
dirty data will affects on miming procedure and led to unreliable and poor
output. Therefore it is important for some data cleaning routines.
How to handle noisy data in data mining?
• Following
methods are used for handling noisy data:
1. Ignore the tuple: Usually
done when the class label is missing. This method is not good unless the tuple
contains several attributes with missing values.
2. Fill in the missing value manually : It is
time-consuming and not suitable for a large data set with many missing values.
3. Use a global constant to fill in the missing
value: Replace all missing attribute values by the same constant.
4. Use the attribute mean to fill in the
missing value: For example, suppose that the average salary
of staff is Rs 65000/-. Use this value to replace the missing value for salary.
5. Use
the attribute mean for all samples belonging to the same class as the given
tuple.
6. Use the most probable value to fill in the
missing value.
Correct Errors as Early as Possible
• If
error is not corrected in early stage of project, then it create problem in
latter stages. Most of the time, we spend on finding and correcting error.
Retrieving data is a difficult task and organizations spend millions of dollars
on it in the hope of making better decisions. The data collection process is
errorprone and in a big organization it involves many steps and teams.
• Data
should be cleansed when acquired for many reasons:
a) Not
everyone spots the data anomalies. Decision-makers may make costly mistakes on
information based on incorrect data from applications that fail to correct for
the faulty data.
b) If
errors are not corrected early on in the process, the cleansing will have to be
done for every project that uses that data.
c) Data
errors may point to a business process that isn't working as designed.
d) Data
errors may point to defective equipment, such as broken transmission lines and
defective sensors.
e) Data
errors can point to bugs in software or in the integration of software that may
be critical to the company
Combining Data from Different Data Sources
1. Joining table
•
Joining tables allows user to combine the information of one observation found
in one table with the information that we find in another table. The focus is
on enriching a single observation.
• A
primary key is a value that cannot be duplicated within a table. This means
that one value can only be seen once within the primary key column. That same
key can exist as a foreign key in another table which creates the relationship.
A foreign key can have duplicate instances within a table.
• Fig.
1.6.2 shows Joining two tables on the CountryID and CountryName keys.

2. Appending tables
• Appending
table is called stacking table. It effectively adding observations from one
table to another table. Fig. 1.6.3 shows Appending table. (See Fig. 1.6.3 on
next page)
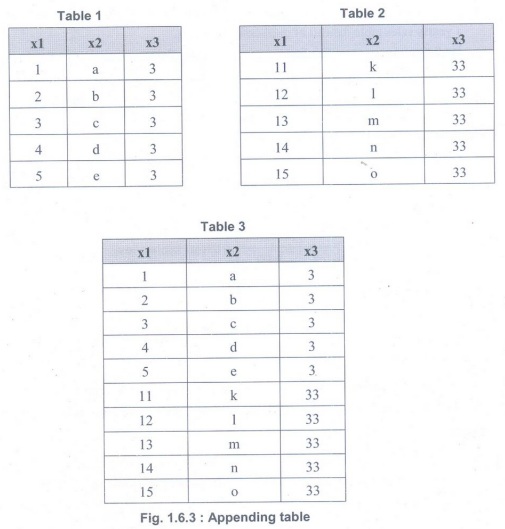
• Table
1 contains x3 value as 3 and Table 2 contains x3 value as 33.The result of
appending these tables is a larger one with the observations from Table 1 as
well as Table 2. The equivalent operation in set theory would be the union and
this is also the command in SQL, the common language of relational databases.
Other set operators are also used in data science, such as set difference and
intersection.
3. Using views to simulate data joins and
appends
•
Duplication of data is avoided by using view and append. The append table
requires more space for storage. If table size is in terabytes of data, then it
becomes problematic to duplicate the data. For this reason, the concept of a
view was invented.
• Fig.
1.6.4 shows how the sales data from the different months is combined virtually
into a yearly sales table instead of duplicating the data.
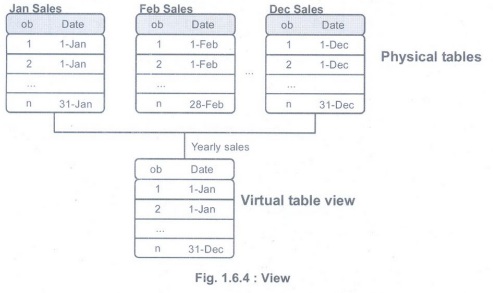
Transforming Data
• In
data transformation, the data are transformed or consolidated into forms
appropriate for mining. Relationships between an input variable and an output
variable aren't always linear.
•
Reducing the number of variables: Having too many variables in the model makes
the model difficult to handle and certain techniques don't perform well when
user overload them with too many input variables.
• All
the techniques based on a Euclidean distance perform well only up to 10
variables. Data scientists use special methods to reduce the number of variables
but retain the maximum amount of data.
Euclidean distance :
•
Euclidean distance is used to measure the similarity between observations. It
is calculated as the square root of the sum of differences between each point.
Euclidean
distance = √(X1-X2)2 + (Y1-Y2)2
Turning variable into dummies :
• Variables
can be turned into dummy variables. Dummy variables canonly take two values:
true (1) or false√ (0). They're used to
indicate the absence of acategorical effect that may explain the observation.
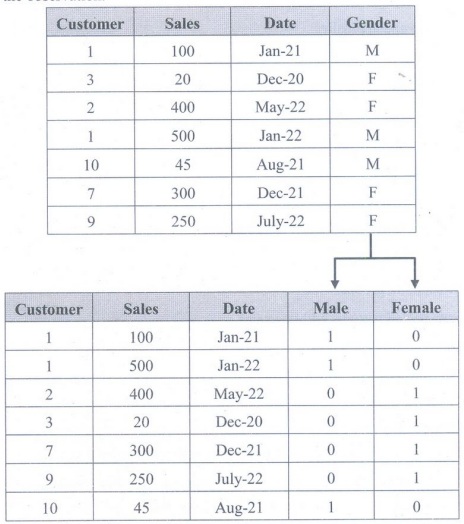
Foundation of Data Science: Unit I: Introduction : Tag: : Operations | Data Science - Data Preparation
Related Topics
Related Subjects

Foundation of Data Science
CS3352 3rd Semester CSE Dept | 2021 Regulation | 3rd Semester CSE Dept 2021 Regulation