Foundation of Data Science: Unit I: Introduction
Data Mining
Reasons for using, Functions, Mining Tasks, Architecture, classification
Data mining refers to extracting or mining knowledge from large amounts of data.
Data Mining
• Data
mining refers to extracting or mining knowledge from large amounts of data. It
is a process of discovering interesting patterns or Knowledge from a large
amount of data stored either in databases, data warehouses or other information
repositories.
Reasons for using data mining:
1.
Knowledge discovery: To identify the invisible correlation, patterns in the
database.
2. Data
visualization: To find sensible way of displaying data.
3. Data
correction: To identify and correct incomplete and inconsistent data.
Functions of Data Mining
• Different
functions of data mining are characterization, association and correlation
analysis, classification, prediction, clustering analysis and evolution
analysis.
1.
Characterization is a summarization of the general characteristics or features
of a target class of data. For example, the characteristics of students can be
produced, generating a profile of all the University in first year engineering
students.
2.
Association is the discovery of association rules showing attribute-value
conditions that occur frequently together in a given set of data.
3.
Classification differs from prediction. Classification constructs a set of
models that describe and distinguish data classes and prediction builds a model
to predict some missing data values.
4.
Clustering can also support taxonomy formation. The organization of
observations into a hierarchy of classes that group similar events together.
5. Data
evolution analysis describes and models' regularities for objects whose
behaviour changes over time. It may include characterization, discrimination,
association, classification or clustering of time-related data.
Data
mining tasks can be classified into two categories: descriptive and predictive.
Predictive Mining Tasks
• To
make prediction, predictive mining tasks performs inference on the current
data. Predictive analysis provides answers of the future queries that move
across using historical data as the chief principle for decisions
• It
involves the supervised learning functions used for the prediction of the
target value. The methods fall under this mining category are the
classification, time-series analysis and regression.
• Data
modeling is the necessity of the predictive analysis, which works by utilizing
some variables to anticipate the unknown future data values for other
variables.
• It
provides organizations with actionable insights based on data. It provides an
estimation regarding the likelihood of a future outcome.
• To do
this, a variety of techniques are used, such as machine learning, data mining,
modeling and game theory.
•
Predictive modeling can, for example, help to identify any risks or
opportunities in the future.
•
Predictive analytics can be used in all departments, from predicting customer
behaviour in sales and marketing, to forecasting demand for operations or
determining risk profiles for finance.
• A very
well-known application of predictive analytics is credit scoring used by
financial services to determine the likelihood of customers making future
credit payments on time. Determining such a risk profile requires a vast amount
of data, including public and social data.
• Historical
and transactional data are used to identify patterns and statistical models and
algorithms are used to capture relationships in various datasets.
• Predictive
analytics has taken off in the big data era and there are many tools available
for organisations to predict future outcomes.
Descriptive Mining Task
•
Descriptive Analytics is the conventional form of business intelligence and
data analysis, seeks to provide a depiction or "summary view" of
facts and figures in an understandable format, to either inform or prepare data
for further analysis.
• Two
primary techniques are used for reporting past events : data aggregation and
data mining.
• It
presents past data in an easily digestible format for the benefit of a wide
business audience.
• A set
of techniques for reviewing and examining the data set to understand the data
and analyze business performance.
• Descriptive
analytics helps organisations to understand what happened in the past. It helps
to understand the relationship between product and customers.
• The
objective of this analysis is to understanding, what approach to take in the
future. If we learn from past behaviour, it helps us to influence future
outcomes.
• It
also helps to describe and present data in such format, which can be easily
understood by a wide variety of business readers.
Architecture of a Typical Data Mining System
• Data
mining refers to extracting or mining knowledge from large amounts of data. It
is a process of discovering interesting patterns or knowledge from a large
amount of data stored either in databases, data warehouses.
• It is
the computational process of discovering patterns in huge data sets involving
methods at the intersection of AI, machine learning, statistics and database
systems.
• Fig.
1.10.1 (See on next page) shows typical architecture of data mining system.
•
Components of data mining system are data source, data warehouse server, data
mining engine, pattern evaluation module, graphical user interface and
knowledge base.
• Database,
data warehouse, WWW or other information repository: This is set of databases,
data warehouses, spreadsheets or other kinds of data repositories. Data
cleaning and data integration techniques may be apply on the data.

• Data warehouse server based on the user's data request, data warehouse
server is responsible for fetching the relevant data.
•
Knowledge base is helpful in the whole data mining process. It might be useful
for guiding the search or evaluating the interestingness of the result
patterns. The knowledge base might even contain user beliefs and data from user
experiences that can be useful in the process of data mining.
• The
data mining engine is the core component of any data mining system. It consists
of a number of modules for performing data mining tasks including association,
classification, characterization, clustering, prediction, time-series analysis
etc.
• The
pattern evaluation module is mainly responsible for the measure of
interestingness of the pattern by using a threshold value. It interacts with
the data mining engine to focus the search towards interesting patterns.
• The graphical user interface module communicates between the user and the data mining system. This module helps the user use the system easily and efficiently without knowing the real complexity behind the process.
• When
the user specifies a query or a task, this module interacts with the data
mining system and displays the result in an easily understandable manner.
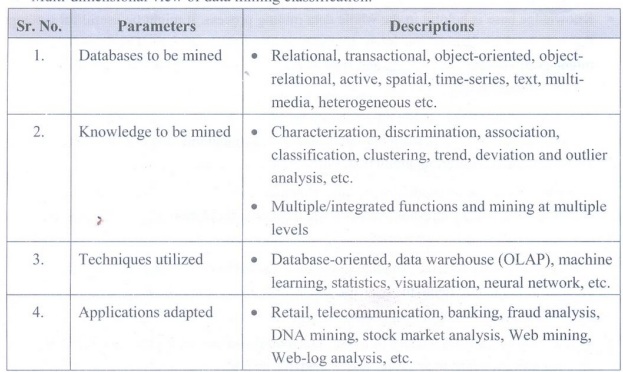
Classification of DM System
• Data
mining system can be categorized according to various parameters. These are
database technology, machine learning, statistics, information science,
visualization and other disciplines.
• Fig.
1.10.2 shows classification of DM system.

• Multi-dimensional
view of data mining classification.
Foundation of Data Science: Unit I: Introduction : Tag: : Reasons for using, Functions, Mining Tasks, Architecture, classification - Data Mining
Related Topics
Related Subjects

Foundation of Data Science
CS3352 3rd Semester CSE Dept | 2021 Regulation | 3rd Semester CSE Dept 2021 Regulation